2023
04-28
04-28
dbGaP加密数据权限申请和数据解密
 我们在NCBI、TCGA、GEO等数据库下载数据时,经常遇到controlled access(限制下载)的数据,不知道怎么弄,有时选择其他可以下载的数据代替,或者直接放弃了。其实这些数据库都是需要通过dbGaP申请下载权限的。这里就以NCBI为例给大家介绍一下dbGaP数据权限申请过程,以及数据下载解密时要注意的地方。Step1:获取账号dbgap账号需要NCI/NIH...阅读全文>&g... 阅 读 全 部 >
我们在NCBI、TCGA、GEO等数据库下载数据时,经常遇到controlled access(限制下载)的数据,不知道怎么弄,有时选择其他可以下载的数据代替,或者直接放弃了。其实这些数据库都是需要通过dbGaP申请下载权限的。这里就以NCBI为例给大家介绍一下dbGaP数据权限申请过程,以及数据下载解密时要注意的地方。Step1:获取账号dbgap账号需要NCI/NIH...阅读全文>&g... 阅 读 全 部 >
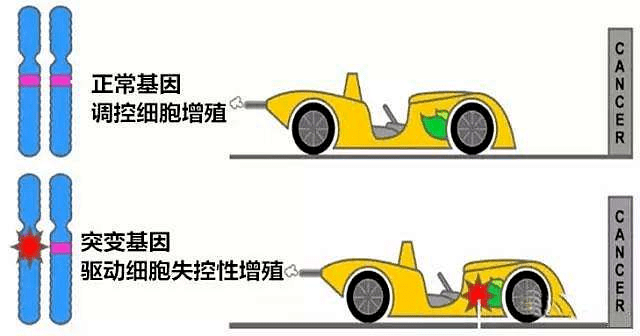 一般认为,癌症是一类基因疾病。基因对细胞生长的调控就像开车,有两大类基因进行调控,分别是“加油基因”和“刹车基因”。“加油基因”负责保持生长速度,让身体的细胞不断得到更新;“刹车基因”负责减缓或者终止细胞生长,以供新生细胞代替原来功能。某些“加油基因”或者“刹车基因”突变后就会对癌症的发生和发展过程起到推动作用且影响显著,这类基因就是肿瘤驱动基因(driver gene),而不会直接导致癌症发.....
一般认为,癌症是一类基因疾病。基因对细胞生长的调控就像开车,有两大类基因进行调控,分别是“加油基因”和“刹车基因”。“加油基因”负责保持生长速度,让身体的细胞不断得到更新;“刹车基因”负责减缓或者终止细胞生长,以供新生细胞代替原来功能。某些“加油基因”或者“刹车基因”突变后就会对癌症的发生和发展过程起到推动作用且影响显著,这类基因就是肿瘤驱动基因(driver gene),而不会直接导致癌症发.....  癌症是一种多阶段的遗传和表观遗传疾病,病因复杂,涉及癌基因和抑癌基因的突变、下调、过表达和缺失等多方面[1]。癌症基因组学的发展已经确认了数千个可能的癌症驱动基因(drivergene),这些基因的突变可以促进肿瘤的发生。一个典型的肿瘤包含2到8个这样的“驱动基因”突变,剩下的突变则是不提供选择性生长优势的“乘客”,驱动基因调节着肿瘤的细胞命运、细胞存活和基因组维持等重要的细胞过程[2]...阅读...
癌症是一种多阶段的遗传和表观遗传疾病,病因复杂,涉及癌基因和抑癌基因的突变、下调、过表达和缺失等多方面[1]。癌症基因组学的发展已经确认了数千个可能的癌症驱动基因(drivergene),这些基因的突变可以促进肿瘤的发生。一个典型的肿瘤包含2到8个这样的“驱动基因”突变,剩下的突变则是不提供选择性生长优势的“乘客”,驱动基因调节着肿瘤的细胞命运、细胞存活和基因组维持等重要的细胞过程[2]...阅读... 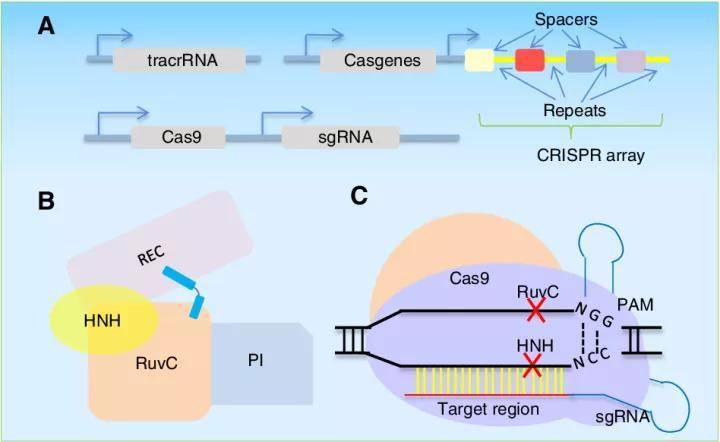 基因是一切生命活动的源头,对于生命科学的研究,只要找到目标基因,就能针对性地开展这个基因的功能、机制以及后续表达等一系列研究。研究基因在代谢通路或某些特定疾病发生过程中的功能,对于疾病机理研究及药物研发具有非常重要的意义。近年来,CRISPR基因编辑技术以其操作简单和通用的独特优势,已发展为研究分子生物学机制的强有力工具。利用CRISPR技术建立可能与某类功能相关的突变体库,通过功能性筛选和......
基因是一切生命活动的源头,对于生命科学的研究,只要找到目标基因,就能针对性地开展这个基因的功能、机制以及后续表达等一系列研究。研究基因在代谢通路或某些特定疾病发生过程中的功能,对于疾病机理研究及药物研发具有非常重要的意义。近年来,CRISPR基因编辑技术以其操作简单和通用的独特优势,已发展为研究分子生物学机制的强有力工具。利用CRISPR技术建立可能与某类功能相关的突变体库,通过功能性筛选和...... 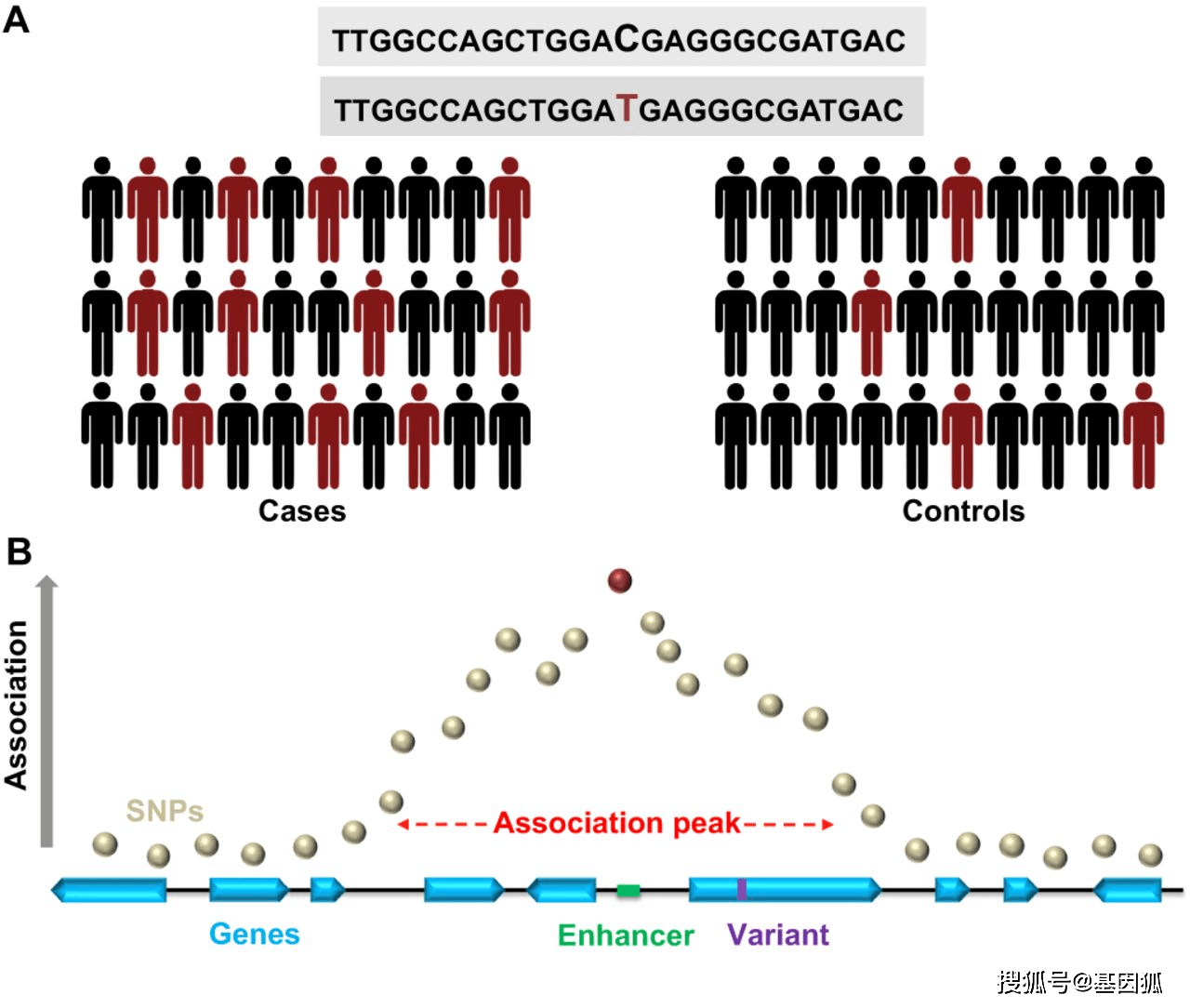 全基因组关联分析(GWAS, Genome-wide association studies)是研究复杂疾病的遗传基础的策略之一。在肿瘤研究领域中,几乎所有常见恶性肿瘤的GWAS均已完成,并确定了与风险增加相关的450多个遗传变异。这些研究不仅揭示了致癌的新途径,而且还表明了常见的遗传变异大幅增加了许多常见癌症的遗传风险。GWAS有望应用于药物研发和癌症预防,助力精准预测、诊断和治疗。当...阅读...
全基因组关联分析(GWAS, Genome-wide association studies)是研究复杂疾病的遗传基础的策略之一。在肿瘤研究领域中,几乎所有常见恶性肿瘤的GWAS均已完成,并确定了与风险增加相关的450多个遗传变异。这些研究不仅揭示了致癌的新途径,而且还表明了常见的遗传变异大幅增加了许多常见癌症的遗传风险。GWAS有望应用于药物研发和癌症预防,助力精准预测、诊断和治疗。当...阅读...  对于乳腺癌来说,MALAT1到底是抑制了转移还是促进了转移呢?今天就以发表在Nature Genetics这篇“Long noncoding RNA MALAT1 suppresses breast cancer metastasis”文章为切入点,说的是lncRNA MALAT1抑制乳腺癌的转移,问题是大部分文章是说MALAT1促进乳腺癌等肿瘤的转移。到底哪里出问题了呢? 之所以会出现促进转移的...
对于乳腺癌来说,MALAT1到底是抑制了转移还是促进了转移呢?今天就以发表在Nature Genetics这篇“Long noncoding RNA MALAT1 suppresses breast cancer metastasis”文章为切入点,说的是lncRNA MALAT1抑制乳腺癌的转移,问题是大部分文章是说MALAT1促进乳腺癌等肿瘤的转移。到底哪里出问题了呢? 之所以会出现促进转移的... 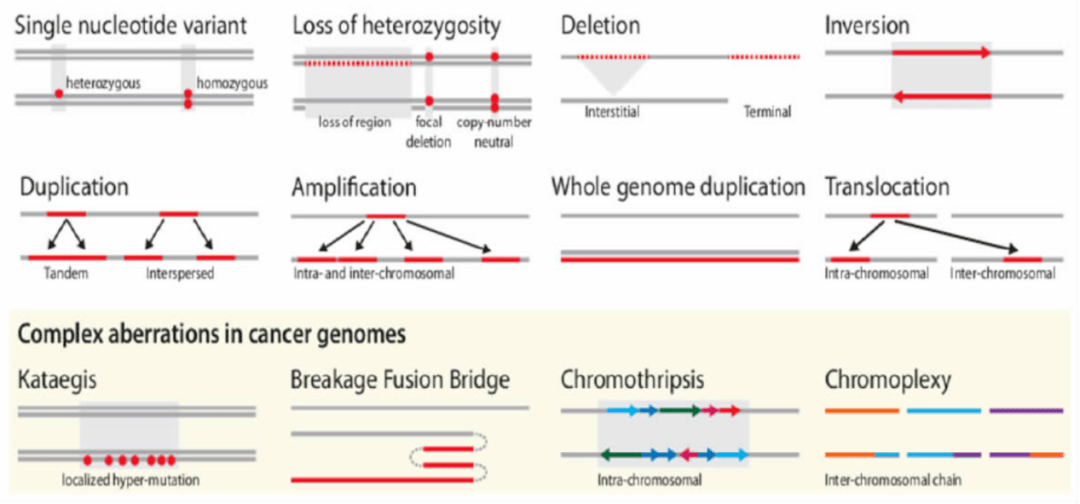 肿瘤突变的类型丰富多样,包括点突变,杂合性缺失,缺失突变,倒位等等。如下图所示:小师妹最近在学习肿瘤克隆进化的过程中,发现人类的点突变的分类与农学里的差异较大,为了厘清这里边的关系,小师妹觉得非常有必要做一个系统的梳理。农学中的点突变,之前在Nature Genetics|从GWAS结果里挖掘候选基因方法微文中有描述,在GWAS定位的LD block中,将所有的SNP分为5类,再一次摘抄下来如下:...
肿瘤突变的类型丰富多样,包括点突变,杂合性缺失,缺失突变,倒位等等。如下图所示:小师妹最近在学习肿瘤克隆进化的过程中,发现人类的点突变的分类与农学里的差异较大,为了厘清这里边的关系,小师妹觉得非常有必要做一个系统的梳理。农学中的点突变,之前在Nature Genetics|从GWAS结果里挖掘候选基因方法微文中有描述,在GWAS定位的LD block中,将所有的SNP分为5类,再一次摘抄下来如下:... 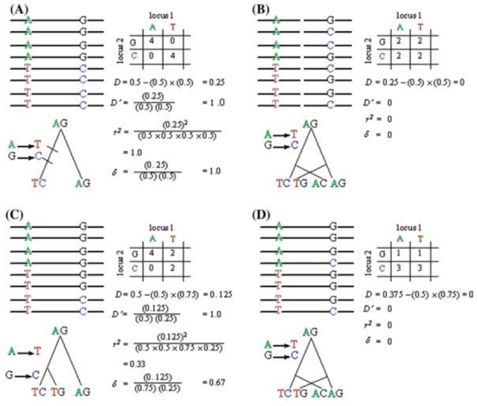 群体遗传学研究中,LD连锁不平衡分析是最常见的分析内容,也是关联分析的基础。在很多的遗传进化GWAS的文章中都会出现LD衰减及单体型block图,如果你还不是很了解的话,是时候补补课了哦~~LD概念当位于某一座位的特定等位基因与另一座位的某一等位基因同时出现的概率大于群体中因随机分布的两个等位基因同时出现的概率时,就称这两个座位处于连锁不平衡状态(linkage disequilibri...阅读...
群体遗传学研究中,LD连锁不平衡分析是最常见的分析内容,也是关联分析的基础。在很多的遗传进化GWAS的文章中都会出现LD衰减及单体型block图,如果你还不是很了解的话,是时候补补课了哦~~LD概念当位于某一座位的特定等位基因与另一座位的某一等位基因同时出现的概率大于群体中因随机分布的两个等位基因同时出现的概率时,就称这两个座位处于连锁不平衡状态(linkage disequilibri...阅读... 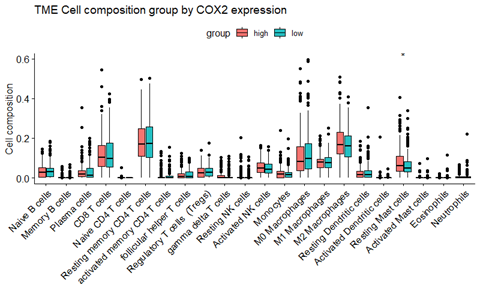 总结目前主流的免疫细胞浸润方法,整理归纳可用的资源及相关代码的实现,以及可视化方式,方便以后查询和分享。这里面提到的免疫浸润分析主要是基于组织样本转录组测序数据或者基因芯片数据的分析。因为我们取到的肿瘤组织并不只是包含肿瘤细胞,其中还有正常细胞、免疫细胞、基质细胞、血管细胞等。不同的细胞具有一些标志性的marker,免疫细胞也是一样。因此,可以根据这些marker基因在组织中的表达...阅读全文&...
总结目前主流的免疫细胞浸润方法,整理归纳可用的资源及相关代码的实现,以及可视化方式,方便以后查询和分享。这里面提到的免疫浸润分析主要是基于组织样本转录组测序数据或者基因芯片数据的分析。因为我们取到的肿瘤组织并不只是包含肿瘤细胞,其中还有正常细胞、免疫细胞、基质细胞、血管细胞等。不同的细胞具有一些标志性的marker,免疫细胞也是一样。因此,可以根据这些marker基因在组织中的表达...阅读全文&... 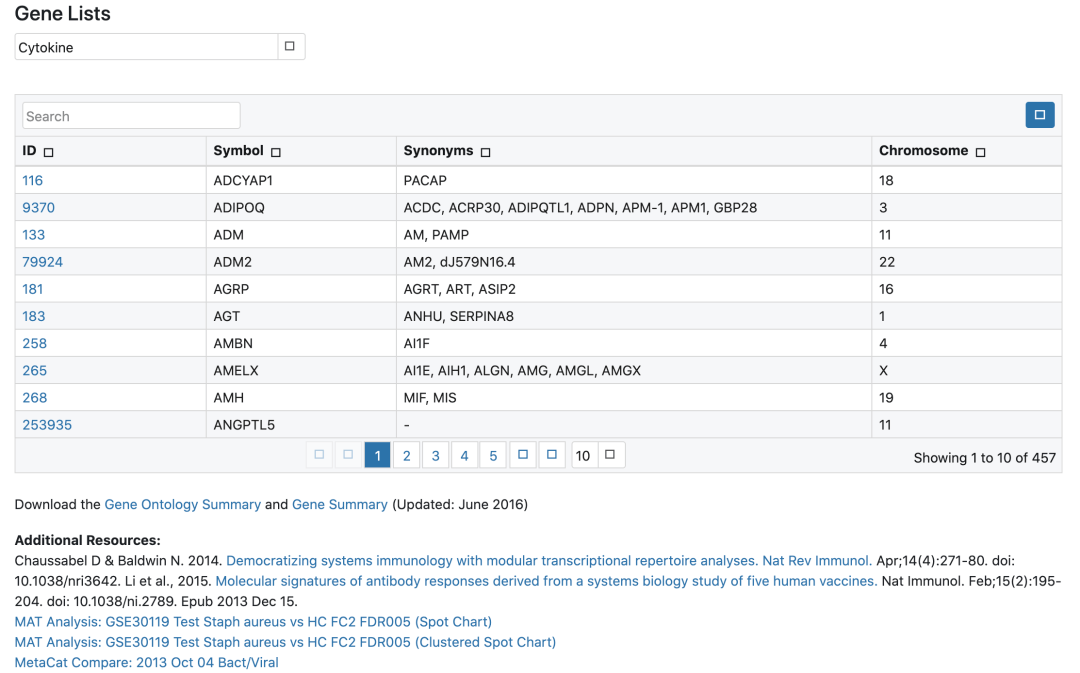 种数据挖掘文章本质上都是要把目标基因集缩小,比如表达量矩阵通常是2万多个蛋白编码基因,不管是表达芯片还是RNA-seq测序的,采用何种程度的差异分析,最后都还有成百上千个目标基因。如果是临床队列,通常是会跟生存分析进行交集,或者多个数据集差异结果的交集,比如:多个数据集整合神器-RobustRankAggreg包 ,这样的基因集就是100个以内的数量了,但是仍然有缩小的空间,比如lasso等统计学...
种数据挖掘文章本质上都是要把目标基因集缩小,比如表达量矩阵通常是2万多个蛋白编码基因,不管是表达芯片还是RNA-seq测序的,采用何种程度的差异分析,最后都还有成百上千个目标基因。如果是临床队列,通常是会跟生存分析进行交集,或者多个数据集差异结果的交集,比如:多个数据集整合神器-RobustRankAggreg包 ,这样的基因集就是100个以内的数量了,但是仍然有缩小的空间,比如lasso等统计学... 