2022
06-04
06-04
30天学会R语言 DAY3: R语言对象(1):向量和矩阵及其操作
 R语言主要分析的对象是数据集,R语言数据集主要是向量、矩阵、数据框、列表、数组等,我们主要介绍前4种。本文先介绍向量和矩阵。一、向量(一维数据) 向量是R语言中最基本的数据对象类型,它可以是数值型、字符型、逻辑值型、复数型。注意:同一向量不能混杂多种不同类型的数据。在医学数据分析中,向量相当于一个变量,向量名为变量名,向量值为变量值。1. 创建向量 通过函数c( )实现向...阅读全文>&g... 阅 读 全 部 >
R语言主要分析的对象是数据集,R语言数据集主要是向量、矩阵、数据框、列表、数组等,我们主要介绍前4种。本文先介绍向量和矩阵。一、向量(一维数据) 向量是R语言中最基本的数据对象类型,它可以是数值型、字符型、逻辑值型、复数型。注意:同一向量不能混杂多种不同类型的数据。在医学数据分析中,向量相当于一个变量,向量名为变量名,向量值为变量值。1. 创建向量 通过函数c( )实现向...阅读全文>&g... 阅 读 全 部 >
 R语言中,绝大多数的函数,是软件提供的,或者R包提供的,可以直接调用R后台的算法,帮助我们进行计算。比如我们计算标准差sd时,无需采用公式去计算,而是调用sd()函数即可。但R语言也提供了一种R函数的编写方法,实在没有找到相应方便函数时,可以自行编写函数,方便计算,我们称之为自定义函数或者自编函数。R入门者实际上无需自己去编写函数,这里只介绍入门,便于以后进行深入学习。• 第11天...阅读全文&...
R语言中,绝大多数的函数,是软件提供的,或者R包提供的,可以直接调用R后台的算法,帮助我们进行计算。比如我们计算标准差sd时,无需采用公式去计算,而是调用sd()函数即可。但R语言也提供了一种R函数的编写方法,实在没有找到相应方便函数时,可以自行编写函数,方便计算,我们称之为自定义函数或者自编函数。R入门者实际上无需自己去编写函数,这里只介绍入门,便于以后进行深入学习。• 第11天...阅读全文&...  在利用R语言统计分析之前,建议诸位复习数据清洗和整理方法,打好基础!今天,我着重对定量定性数据的转换功能进行总结,并推出tidyverse系列包供大家了解。1、 数值变量数据转为分类变量数据数值变量数据经常要转换为分类变量,由于本系列课程分类变量的转换,分散在各处,今天进行汇总。常见的方法如下:# 先读取数据集t1<-read.csv("elder1.csv")...阅读全文>>...
在利用R语言统计分析之前,建议诸位复习数据清洗和整理方法,打好基础!今天,我着重对定量定性数据的转换功能进行总结,并推出tidyverse系列包供大家了解。1、 数值变量数据转为分类变量数据数值变量数据经常要转换为分类变量,由于本系列课程分类变量的转换,分散在各处,今天进行汇总。常见的方法如下:# 先读取数据集t1<-read.csv("elder1.csv")...阅读全文>>...  R语言中,apply族函数是非常重要的函数,它在很多场景下,可以代替循环语句,简化程序写作过程,实现高效的统计分析,因此我们称之为批量处理函数。利用apply族函数可将某函数作用到一系列数据对象上,包括标量、向量、矩阵、多维数组、数据框、列表。我们可以同时纳入多个向量、数据库、列表、变量,进行变量的转换、统计描述。 此外,apply函数另外一个优势是它可以批量开展自编或者系统自带函数的运...阅读...
R语言中,apply族函数是非常重要的函数,它在很多场景下,可以代替循环语句,简化程序写作过程,实现高效的统计分析,因此我们称之为批量处理函数。利用apply族函数可将某函数作用到一系列数据对象上,包括标量、向量、矩阵、多维数组、数据框、列表。我们可以同时纳入多个向量、数据库、列表、变量,进行变量的转换、统计描述。 此外,apply函数另外一个优势是它可以批量开展自编或者系统自带函数的运...阅读...  在所有计算机语言中,条件和循环语句占据着极其重要的地位,在统计软件比如SAS,条件语句在数据整理中的地位也举足轻重。R语言高级编程,条件和循环语句也类似如此。作为初级教程,今天我们就两语句在数据整理做简单的介绍。一、条件语句条件语句,最常见的是 if语句。If语句常见的形式有简单的ifelse 语句 和复杂的if –else if-else语句1. ifelse 语句...阅读全文>>...
在所有计算机语言中,条件和循环语句占据着极其重要的地位,在统计软件比如SAS,条件语句在数据整理中的地位也举足轻重。R语言高级编程,条件和循环语句也类似如此。作为初级教程,今天我们就两语句在数据整理做简单的介绍。一、条件语句条件语句,最常见的是 if语句。If语句常见的形式有简单的ifelse 语句 和复杂的if –else if-else语句1. ifelse 语句...阅读全文>>... 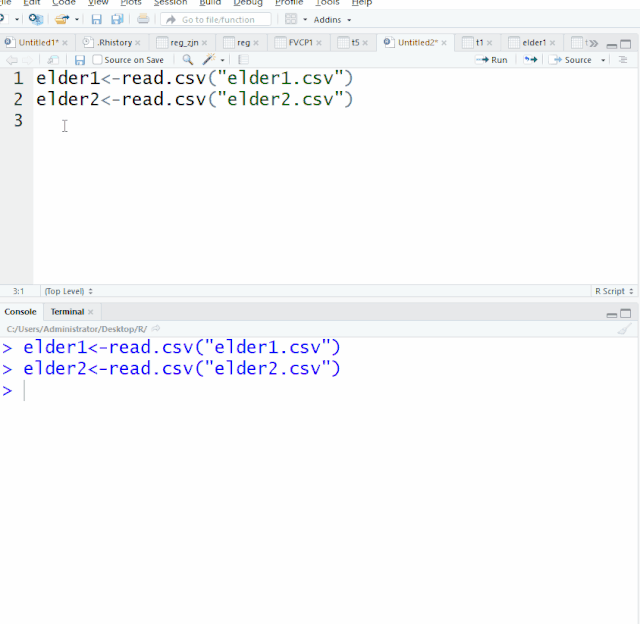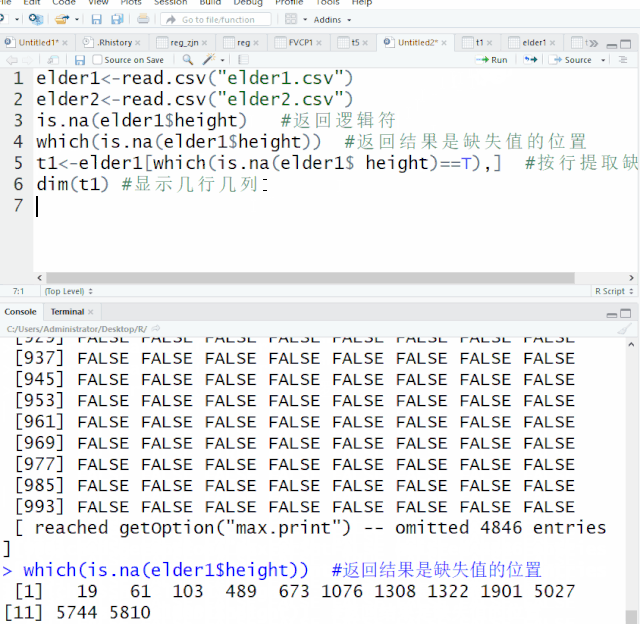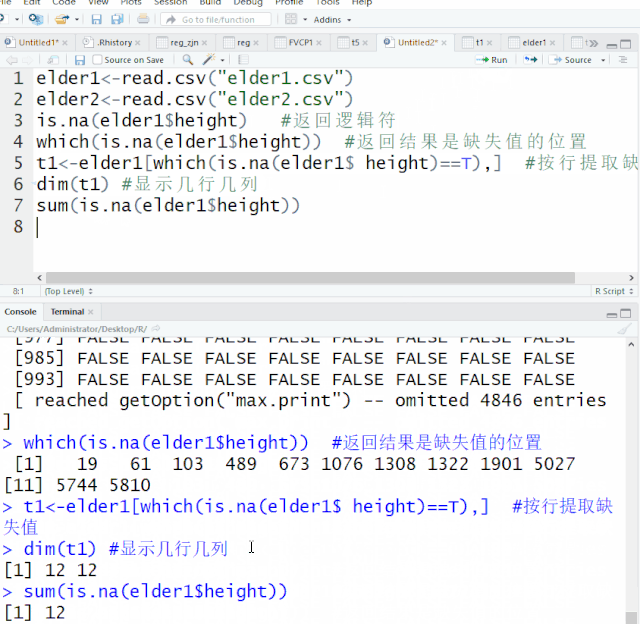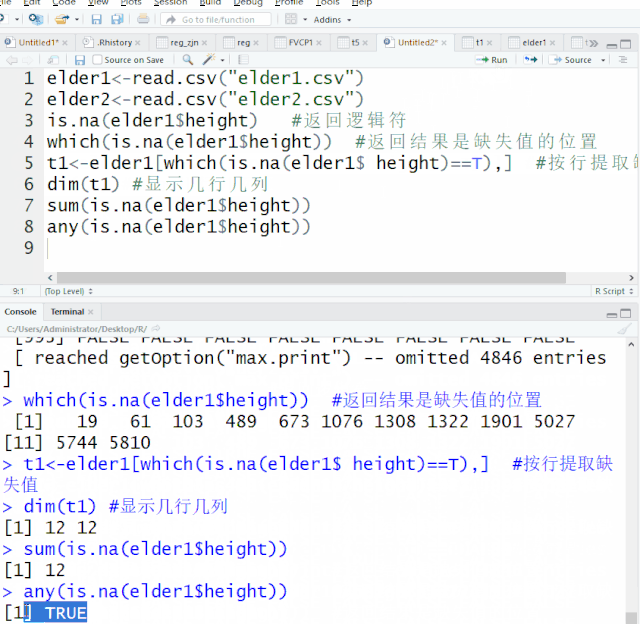 缺失值是数据中普遍存在的现象,信息无法获取、遗漏、异常值都有可能造成数据的缺失。缺失值的存在会影响数据分析,导致结果存在偏差。R语言中,缺失值用NA和NaN表示,最常用的是用NA符号表示该数据遗失、不存在或异常。开始之前,我们先读入elder1、elder2这两个文件elder1<-read.csv("elder1.csv")elder2<-re...阅读全文>>...
缺失值是数据中普遍存在的现象,信息无法获取、遗漏、异常值都有可能造成数据的缺失。缺失值的存在会影响数据分析,导致结果存在偏差。R语言中,缺失值用NA和NaN表示,最常用的是用NA符号表示该数据遗失、不存在或异常。开始之前,我们先读入elder1、elder2这两个文件elder1<-read.csv("elder1.csv")elder2<-re...阅读全文>>...  日常数据整理需要添加变量,对变量进行计算转化。本章将给大家介绍在数据集对原变量进行计算并添加变量及对原变量的数据进行转化。开始之前,我们先读入elder1、elder2这两个文件elder1<-read.csv("elder1.csv")elder2<-read.csv("elder2.csv")一、添加变量数据集$新变量<-...阅读全文>>...
日常数据整理需要添加变量,对变量进行计算转化。本章将给大家介绍在数据集对原变量进行计算并添加变量及对原变量的数据进行转化。开始之前,我们先读入elder1、elder2这两个文件elder1<-read.csv("elder1.csv")elder2<-read.csv("elder2.csv")一、添加变量数据集$新变量<-...阅读全文>>...  在数据进行前期处理中经常会涉及到数据集的合并,变量名、变量属性的更改及变量的排序,这一章就这四个方面给大家做一下简单介绍。开始之前,我们先读入elder1、elder2这两个文件elder1<-read.csv("elder1.csv")elder2<-read.csv("elder2.csv")一、数据集合并rbind(数据集1,...阅读全文>>...
在数据进行前期处理中经常会涉及到数据集的合并,变量名、变量属性的更改及变量的排序,这一章就这四个方面给大家做一下简单介绍。开始之前,我们先读入elder1、elder2这两个文件elder1<-read.csv("elder1.csv")elder2<-read.csv("elder2.csv")一、数据集合并rbind(数据集1,...阅读全文>>... 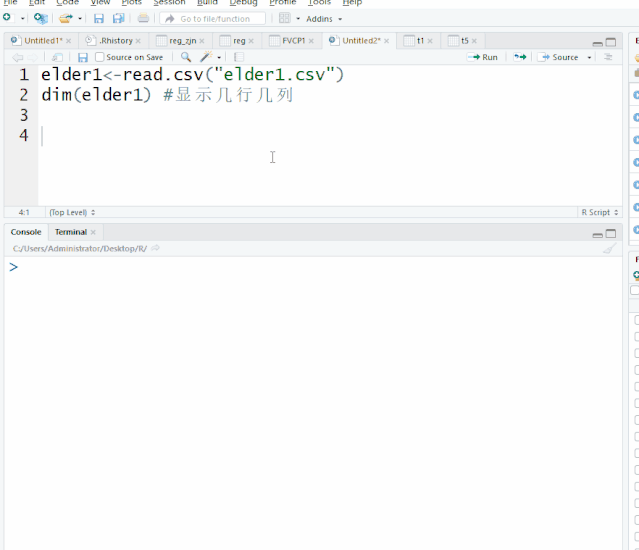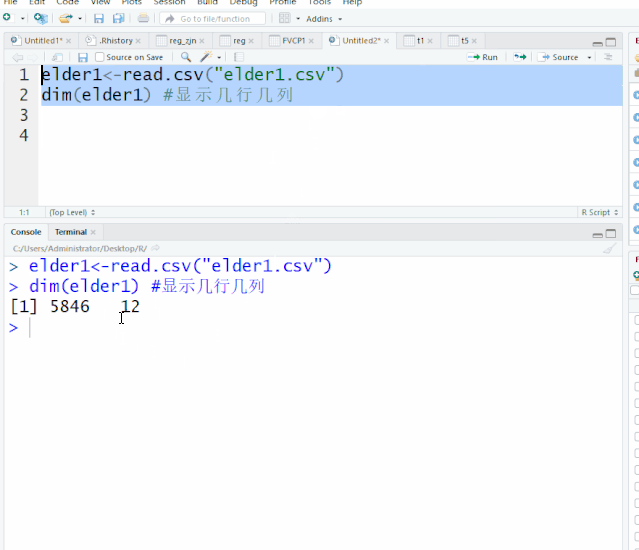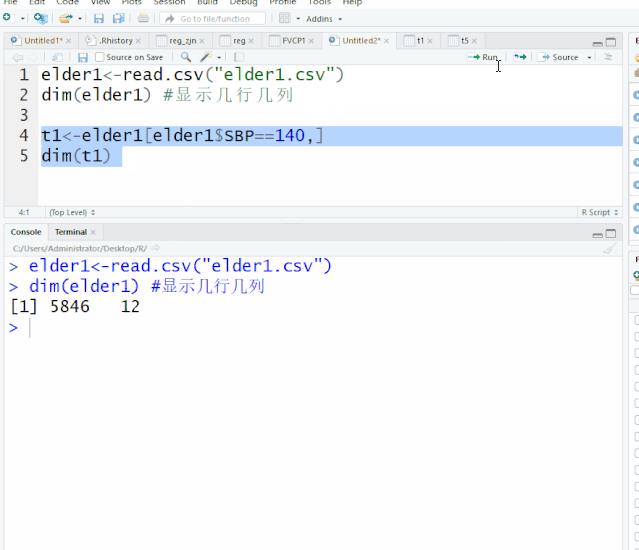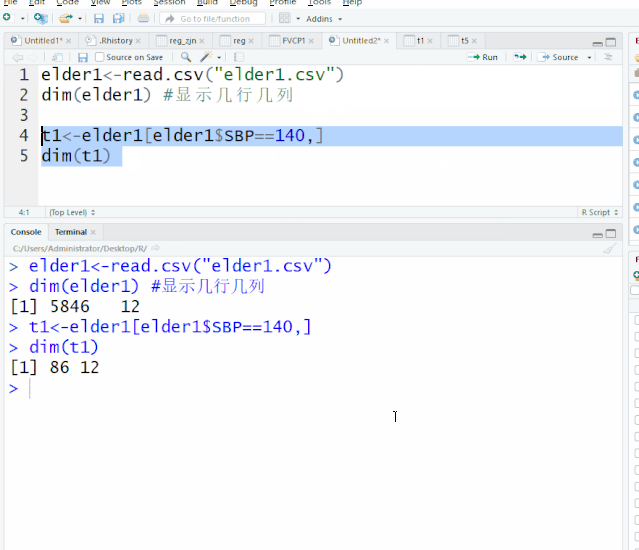 当我们只需要对数据集中的部分数据进行分析,就需要用的数据的提取,这是日常最常用的命令。开始之前,我们先读入elder1这个文件elder1<-read.csv("elder1.csv")dim(elder1) #显示几行几列[1] 5846 12 显示5846行,12列一、 数据提取1. 子集的提取(行的提取)数据集子集提...阅读全文>>...
当我们只需要对数据集中的部分数据进行分析,就需要用的数据的提取,这是日常最常用的命令。开始之前,我们先读入elder1这个文件elder1<-read.csv("elder1.csv")dim(elder1) #显示几行几列[1] 5846 12 显示5846行,12列一、 数据提取1. 子集的提取(行的提取)数据集子集提...阅读全文>>... 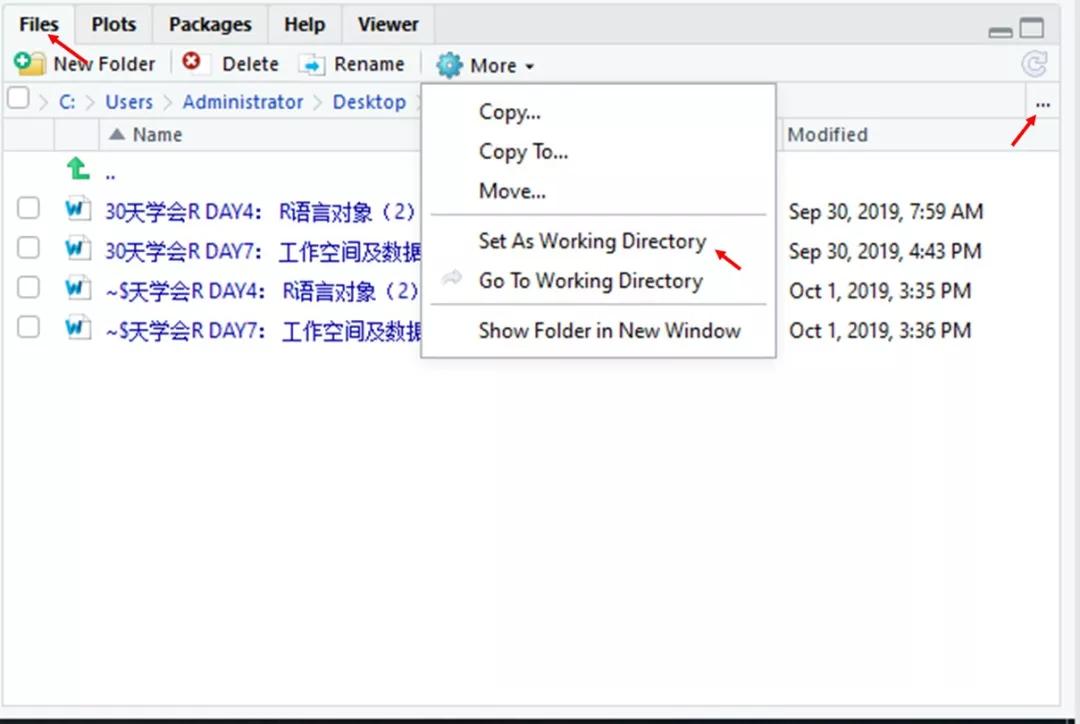 一、 工作空间工作空间,意味着,所有R的程序文件、数据集、其他相关资料都保存在某一个文件夹下面,十分方便提取。在一个R语言程序结束后,工作空间可以保存它的映像,在下次启动R时,该工作空间,包括历史代码就会自动重新加,非常方便。但没次使用的包需要重新加载。1.设置工作空间方法一,采用setwd()语句,设置工作空间,设置的文件夹需事先在硬盘中建立,R语言无法创建新的文件夹。...阅读全文>&g...
一、 工作空间工作空间,意味着,所有R的程序文件、数据集、其他相关资料都保存在某一个文件夹下面,十分方便提取。在一个R语言程序结束后,工作空间可以保存它的映像,在下次启动R时,该工作空间,包括历史代码就会自动重新加,非常方便。但没次使用的包需要重新加载。1.设置工作空间方法一,采用setwd()语句,设置工作空间,设置的文件夹需事先在硬盘中建立,R语言无法创建新的文件夹。...阅读全文>&g... 