2022
09-29
09-29
 蛋白质是调控生命功能的基本层次,在生命科学研究上具有重要意义,因此受到科研工作重点关注!也是很多小伙伴发文的热点方向!但由于执行复杂生命功能的蛋白质的结构和功能等的多样性都很高,收录蛋白质信息的数据库往往各有所侧重。 面对网上一搜,名目繁多的蛋白质数据库,不少小伙伴会无所适从。那么,我们平时使用的那些常用蛋白数据库,都适合来找一些什么数据呢?以下,小编选了一些平时常用的蛋白质数据库,整理给大家。0... 阅 读 全 部 >
蛋白质是调控生命功能的基本层次,在生命科学研究上具有重要意义,因此受到科研工作重点关注!也是很多小伙伴发文的热点方向!但由于执行复杂生命功能的蛋白质的结构和功能等的多样性都很高,收录蛋白质信息的数据库往往各有所侧重。 面对网上一搜,名目繁多的蛋白质数据库,不少小伙伴会无所适从。那么,我们平时使用的那些常用蛋白数据库,都适合来找一些什么数据呢?以下,小编选了一些平时常用的蛋白质数据库,整理给大家。0... 阅 读 全 部 >
 作者:卢平 编辑:Yuki 从数十亿年前的原始单细胞生物开始,地球生命的演化之路就充满着革新:细胞核形成——有性生殖发生——多细胞生命出现——组织分化——器官形成——由海生到陆生……在枝繁叶茂的生命之树上,无数新的功能和结构让众多物种能够适应不同的环境和资源,各居其位。而所有这些创新的根源,几乎都来自于每个细胞中的一套基因组中。 基因组本身是DNA分子长链,可比作一串ATCG四种碱基组合排列... 阅 读 全 部 >
作者:卢平 编辑:Yuki 从数十亿年前的原始单细胞生物开始,地球生命的演化之路就充满着革新:细胞核形成——有性生殖发生——多细胞生命出现——组织分化——器官形成——由海生到陆生……在枝繁叶茂的生命之树上,无数新的功能和结构让众多物种能够适应不同的环境和资源,各居其位。而所有这些创新的根源,几乎都来自于每个细胞中的一套基因组中。 基因组本身是DNA分子长链,可比作一串ATCG四种碱基组合排列... 阅 读 全 部 >
 复杂基因组指的是无法使用常规测序和组装手段直接解析的一类基因组,通常指包含高比例重复序列、高杂合度、极端GC含量、存在难消除异源DNA污染的基因组。为了解决复杂基因组的测序和组装问题,需要分别从基因组测序实验方法、测序技术平台、组装算法与策略3个方面进行深入研究。本文详细介绍了复杂基因组测序组装相关的现有技术与方法,并结合复杂基因组经典实例介绍了复杂基因组测序的技术解决途径和发展历程,可为制订..... 阅 读 全 部 >
复杂基因组指的是无法使用常规测序和组装手段直接解析的一类基因组,通常指包含高比例重复序列、高杂合度、极端GC含量、存在难消除异源DNA污染的基因组。为了解决复杂基因组的测序和组装问题,需要分别从基因组测序实验方法、测序技术平台、组装算法与策略3个方面进行深入研究。本文详细介绍了复杂基因组测序组装相关的现有技术与方法,并结合复杂基因组经典实例介绍了复杂基因组测序的技术解决途径和发展历程,可为制订..... 阅 读 全 部 >
 利用生物信息分析大数据在论文发表中占据了举足轻重的地位,尤其是在高通量测序越来越便宜的今天,但是测序分析中各种名词仍令很多小菜或非生物信息专业的人抓狂。哈哈,不用怕,看了小编今天的文后,这些都不是事儿!先来介绍几个概念性名词:1.高通量测序: 高通量测序技术(High-throughput sequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变, 一次对几十...阅... 阅 读 全 部 >
利用生物信息分析大数据在论文发表中占据了举足轻重的地位,尤其是在高通量测序越来越便宜的今天,但是测序分析中各种名词仍令很多小菜或非生物信息专业的人抓狂。哈哈,不用怕,看了小编今天的文后,这些都不是事儿!先来介绍几个概念性名词:1.高通量测序: 高通量测序技术(High-throughput sequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变, 一次对几十...阅... 阅 读 全 部 >
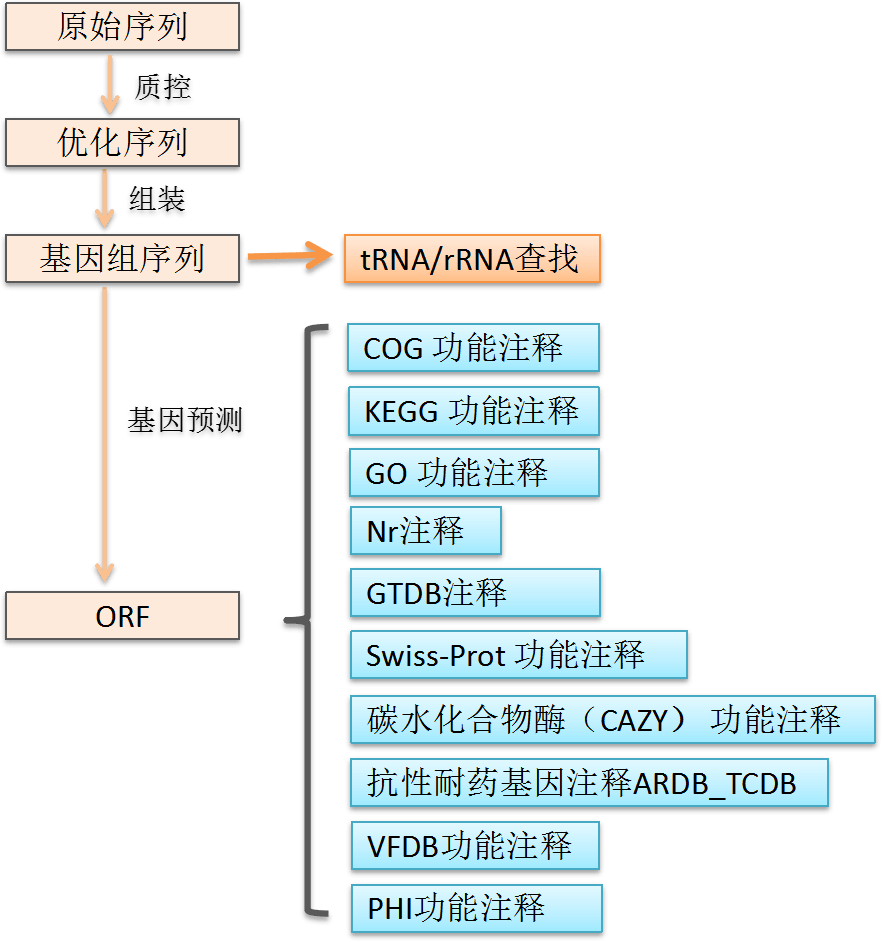 一、 介绍细菌基因组研究,是通过基因组测序和组装,获得细菌全基因组序列,并对基因组开展结构预测,功能注释、比较基因组学及泛基因组研究。依据研究精细程度不同,分为框架图(也称为草图)、完成图(0gap),下面我们主要介绍框架图的分析内容。二、 分析流程基本流程为,建库测序,序列优化,基因组组装,基因及结构预测,功能注释,画图展示。三、 分析步骤与结果展示...阅读全文>>... 阅 读 全 部 >
一、 介绍细菌基因组研究,是通过基因组测序和组装,获得细菌全基因组序列,并对基因组开展结构预测,功能注释、比较基因组学及泛基因组研究。依据研究精细程度不同,分为框架图(也称为草图)、完成图(0gap),下面我们主要介绍框架图的分析内容。二、 分析流程基本流程为,建库测序,序列优化,基因组组装,基因及结构预测,功能注释,画图展示。三、 分析步骤与结果展示...阅读全文>>... 阅 读 全 部 >
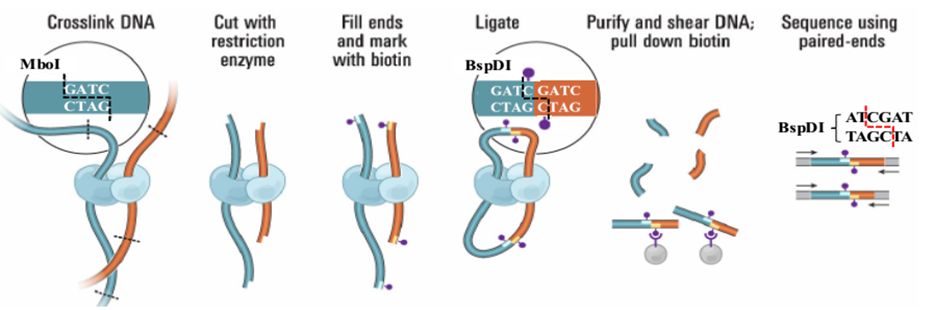 高质量的参考基因组是研究物种进化、性状定位、基因表达调控等生物学问题的基础,但目前二代+三代的测序策略,只能够将基因组组装到Contig/Scaffold水平,无法获得染色体水平的基因组信息。而 Hi-C辅助组装技术可将Contig/Scaffold挂载到不同的染色体上,提升基因组质量,在基因组文章的发表中扮演了不可或缺的角色。 下面,小编将与大家分享一些Hi-C辅助组装技术的小知识...阅读全文... 阅 读 全 部 >
高质量的参考基因组是研究物种进化、性状定位、基因表达调控等生物学问题的基础,但目前二代+三代的测序策略,只能够将基因组组装到Contig/Scaffold水平,无法获得染色体水平的基因组信息。而 Hi-C辅助组装技术可将Contig/Scaffold挂载到不同的染色体上,提升基因组质量,在基因组文章的发表中扮演了不可或缺的角色。 下面,小编将与大家分享一些Hi-C辅助组装技术的小知识...阅读全文... 阅 读 全 部 >
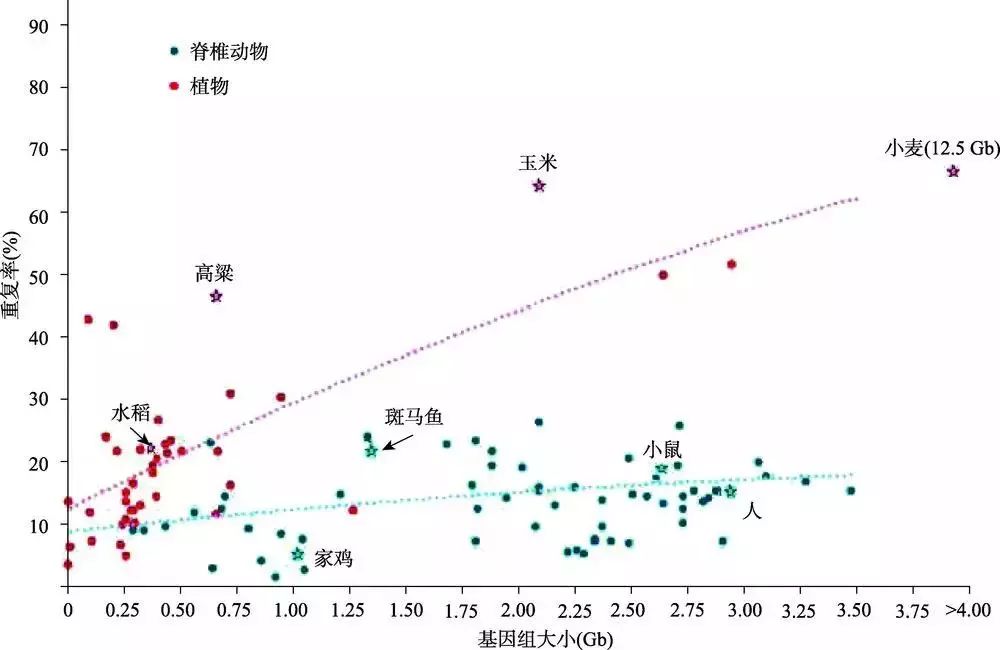
 植物基因组通常具有较高的重复序列,且很多为多倍体,因此组装植物基因组具有一定的挑战性。双子叶模式植物拟南芥、单子叶模式植物水稻基因组序列分别在2000年、2005年公布,它们都是基于BAC克隆及sanger法测序的方法获得的,至今在植物基因组序列中其质量依然是最好的。二代测序技术的出现及发展,极大地加快了植物基因组的研究进程,已经有超过200种植物获得了基因组序列,但是由于二代测序...阅读全文&... 阅 读 全 部 >
植物基因组通常具有较高的重复序列,且很多为多倍体,因此组装植物基因组具有一定的挑战性。双子叶模式植物拟南芥、单子叶模式植物水稻基因组序列分别在2000年、2005年公布,它们都是基于BAC克隆及sanger法测序的方法获得的,至今在植物基因组序列中其质量依然是最好的。二代测序技术的出现及发展,极大地加快了植物基因组的研究进程,已经有超过200种植物获得了基因组序列,但是由于二代测序...阅读全文&... 阅 读 全 部 >
 2019年2月26日,中国科学院植物研究所北方资源植物重点实验室与北京百迈客生物科技有限公司等单位合作,成果以“A Chromosome-Scale Genome Assembly of Paper Mulberry (Broussonetia papyrifera) Reveals the Genetic Basis of Its Forage and Papermaking Usage”为题发... 阅 读 全 部 >
2019年2月26日,中国科学院植物研究所北方资源植物重点实验室与北京百迈客生物科技有限公司等单位合作,成果以“A Chromosome-Scale Genome Assembly of Paper Mulberry (Broussonetia papyrifera) Reveals the Genetic Basis of Its Forage and Papermaking Usage”为题发... 阅 读 全 部 >
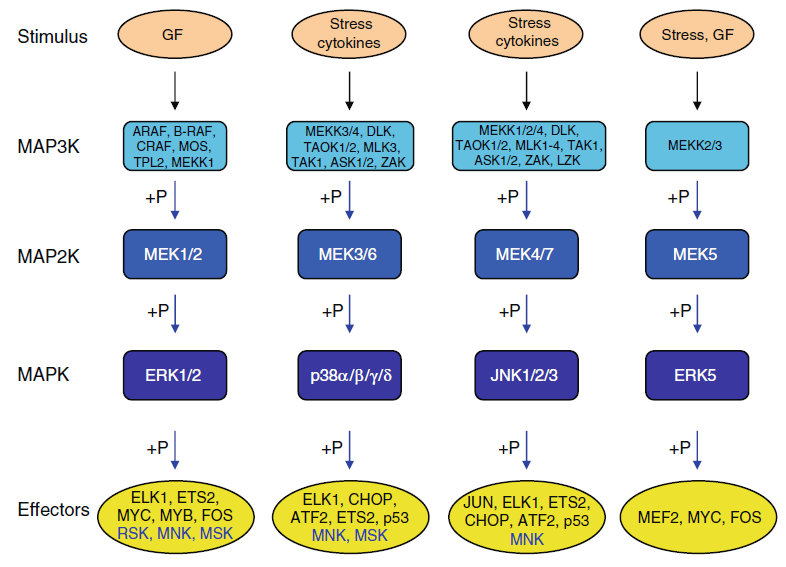
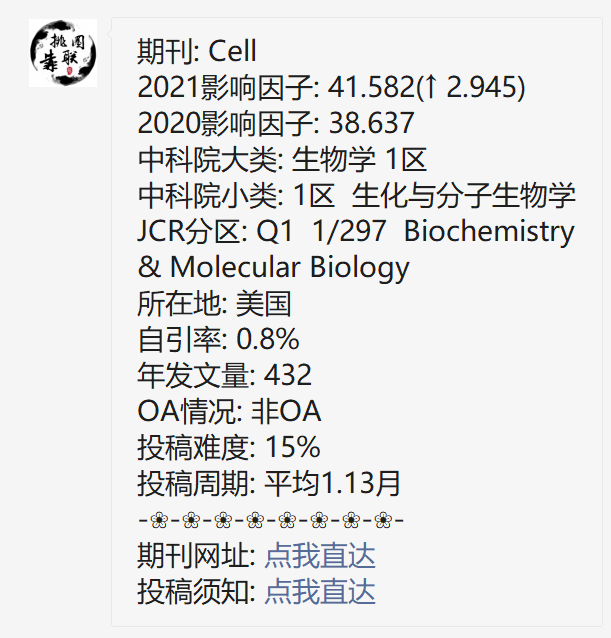 领略高端套路,发表高分文章!今天带给大家的是一篇于2021年1月发表在《Cell》上的高分生信文章,题目是“ A modular master regulator landscape controls cancer tranional identity”。 期刊简介数据来源 & 思路框架本项研究意在将基因组的改变与癌细胞转录的特性联系起... 阅 读 全 部 >
领略高端套路,发表高分文章!今天带给大家的是一篇于2021年1月发表在《Cell》上的高分生信文章,题目是“ A modular master regulator landscape controls cancer tranional identity”。 期刊简介数据来源 & 思路框架本项研究意在将基因组的改变与癌细胞转录的特性联系起... 阅 读 全 部 >

生信圈
欢迎您支持我的公众号
点击此处可关闭
 [该文章已设置加密,请点击标题输入密码访问]...
[该文章已设置加密,请点击标题输入密码访问]...