这些周R语言学习,记录如下。
01
数据操作概述
数据操作是一个对数据加工处理以满足后续数据工作(分析或者建模)的过程。
数据操作主要做的事情,包括:
数据列的操作。
数据行的操作。
数据的聚合操作。
数据的其它操作。
我用dplyr包做数据操作,它功能强大,应用简便,编码易懂。
dplyr包做各种数据操作,无论多复杂,都可以分解5种基本的数据操作组合:
select——选择列
filter/slice——选择行
arrange——对行排序
mutate——修改列/增加列
summarize——数据聚合运算
它们都可以与
group_by——分组
结合使用,以改变数据操作的作用域:
是作用于整个数据框,还是作用于数据框的每个分组。
上述函数组合使用,可以实现各种数据操作,不管是简单的,还是复杂的,都可以很好处理。
这些函数的相同之处:
第1个参数是数据框,便于管道操作,形如(df %>% select)
根据列名访问数据框的列,列名不用加引号
返回结果是一个新的数据框,不改变原数据框
从而,可以方便地实现:
把多个简单操作,依次用管道连接,实现复杂的数据操作。
02
列操作
数据的列操作,主要包括这些任务:
列选择
列删除
列顺序调整
列重命名
多列用函数处理
列增加
2.1 列选择
列选择,就是从数据集中选择所需列。
使用select函数
1)用列名或者索引确定目标列
代码演示
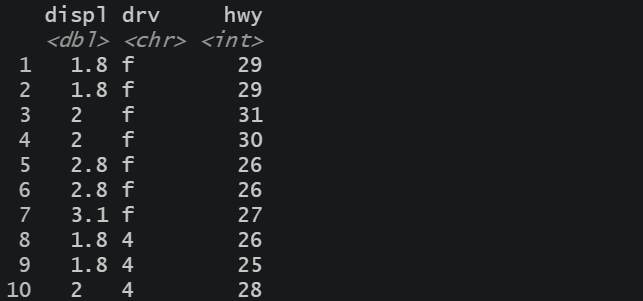
mpg%>%
select(displ, drv, hwy) %>%
head(n = 10)
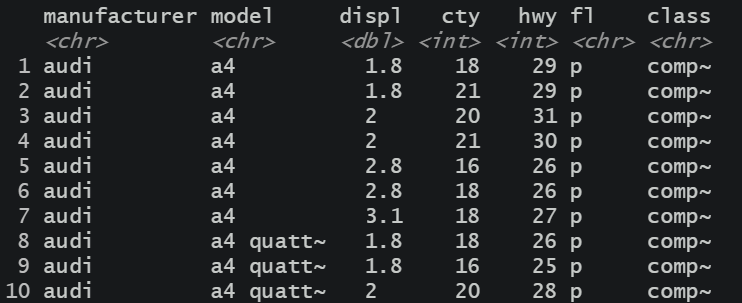
mpg %>%
select( 3, 7, 9) %>%
head(n = 10)
2)用运算符确定目标列
用:选择连续的若干列
用!选择变量集合的余集
&和|选择变量的交集或者并集
c合并多个选择
代码演示
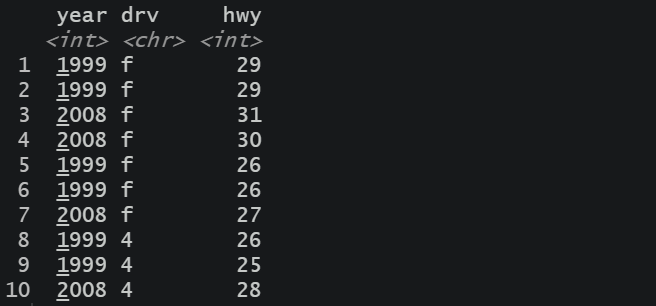
mpg %>%
select( year:drv) %>%
head(n = 10)
mpg %>%
select(! year:drv) %>%
head(n = 10)
mpg %>%
select(c( year, drv, hwy)) %>%
head(n = 10)

3)用函数确定目标列
选择指定的列
everything——选择所有列
last_col——选择最后一列,可以带参数
选择列名匹配的列
starts_with——以某前缀开头的列
ends_with——以某后缀结尾的列
contains——包含正则表达式的列
matches——匹配正则表达式的列
num_ranges——匹配数值范围的列
结合函数选择列
where——应用一个函数到所有列,选择返回结果为TRUE的列
代码演示
mpg %>%
select(starts_with( "m")) %>%
head(n = 10)
mpg %>%
select(ends_with( "s")) %>%
head(n = 10)
mpg %>%
select(contains( "c")) %>%
head(n = 10)
mpg %>%
select(contains( "c") | ends_with( "s")) %>%
head(n = 10)
mpg %>%
select(matches( "m.*e")) %>%
head(n = 10)
mpg %>%
select( where( is.numeric)) %>%
head(n = 10)
mpg %>%
select( where( is.numeric)) %>%
select( where(~ sum(.x, na.rm = TRUE) > 1000)) %>%
head(n = 10)
2.2 列删除
列删除,就是从数据集中删除不需要的列。
用减号(-)删除列
代码演示
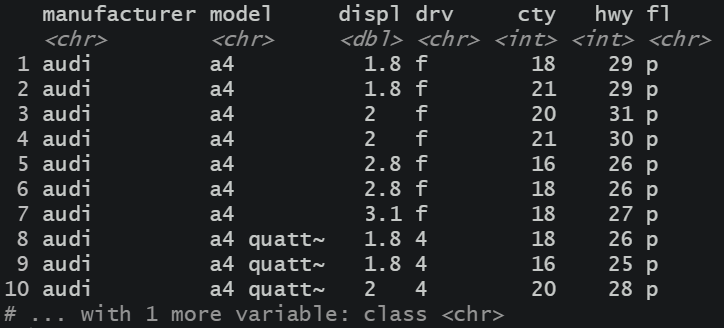
mpg%>%
select(-c(year, cyl, trans)) %>%
head(n = 10)
2.3 列顺序调整
可以根据被选择列的顺序调整列的顺序
代码演示
mpg %>%
select(ends_with( "s"), year, hwy) %>%
head(n = 10)
mpg %>%
select( year, everything) %>%
head(n = 10)
mpg %>%
relocate(where( is.numeric), .after = manufacturer) %>%
head(n = 10)
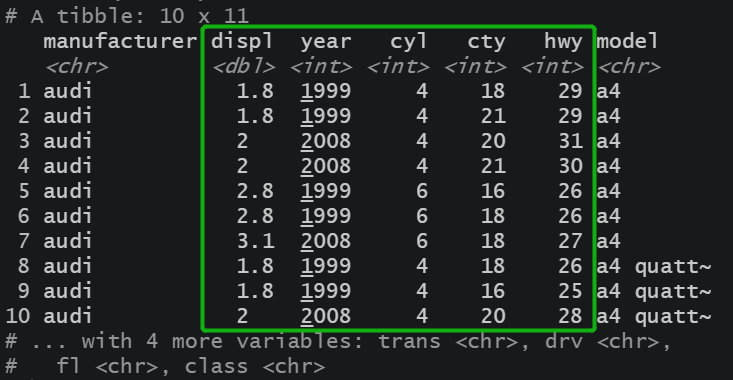
2.4 列重命名
使用set_names函数为所有列重命名
使用rename函数为部分列重命名,格式:新名 = 旧名
使用rename_with(.data, .fn, .cols)函数为选中cols采用函数fn对列重命名
代码演示
economics %>%
set_names(paste0( "x", 1: 6)) %>%
head(n = 10)
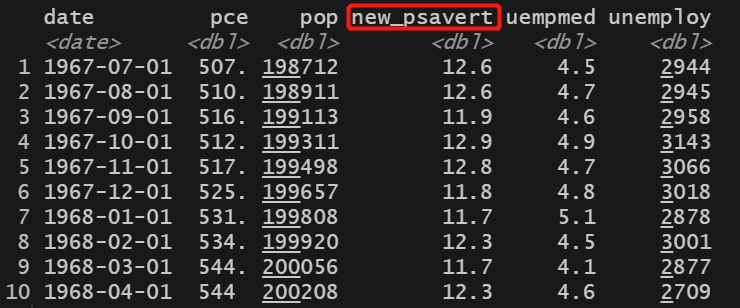
economics %>%
rename(日期 = date) %>%
head(n = 10)
economics %>%
rename_with( ~ paste0( "new_", .x), matches( "s")) %>%
head(n = 10)
2.5 多列用函数处理
使用强大的 across函数。
可以让0个或1个或多个函数作用所选择的列,即同时对所选择的多列应用若干函数。
across函数的基本格式:

across函数工作示意图:
across函数的分解思维:
想要同时修改多列,只需要选出多列,把对一列做的事情写成函数即可,然后交给across就行了。
代码演示
iris
# 获取iris数据集不同类别Sepal的长和宽的均值
iris %>%
select(starts_with( "S")) %>%
group_by(Species) %>%
summarise(Sepal_Length_Mean = mean(Sepal.Length, na.rm = TRUE),
Sepal_Width_Mean = mean(Sepal.Width, na.rm = TRUE))
# 使用across函数
iris %>%
select(starts_with( "S")) %>%
group_by(Species) %>%
summarise(across(c(Sepal.Length, Sepal.Width), mean, na.rm = TRUE))
2.6 列增加
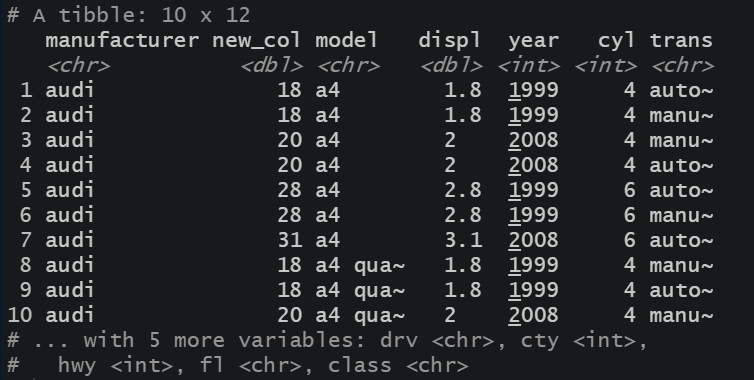
用mutate函数增加新列,返回原数据框并增加新列,默认加在最后一列。
参数.before,.after可以设置新列的位置。
代码演示
# 列增加
names(mpg)
mpg%>%
mutate(new_col = displ * 10) %>%
head(n = 10)
mpg%>%
mutate(new_col = displ * 10, .before = model) %>%
head(n = 10)
mpg%>% mutate(new_col = displ * 10, .after = manufacturer) %>%
head(n = 10)
03
行操作
行操作,就是获取数据子集。
行操作,包括这些任务。
行过滤
行切片
行删除
行排序
3.1 行过滤
用filter函数,根据条件选择行
代码演示
mpg%>%
filter(model == 'a4') %>%
head(n = 5)
mpg %>%
filter(model == 'a4', year == 1999) %>%
head
mpg %>%
filter(model == 'a4', (year == 1999| drv == 'f')) %>%
head
# 闭区间,between函数
mpg %>%
filter(between(year, 1999, 2004)) %>%
head
在限定列范围下做行选择
用if_all或者if_any函数与filter函数结合。
代码演示
# 选择第8 -9列,所有值都>20的行
mpg%>%
filter( if_all(8 :9, ~ .x> 20)) %>%
head
# 所有列范围,所有制都不是 NA的行,类似 na.omit函数
mpg%>%
filter( if_all( everything, ~ ! is.na( .x))) %>%
head
# 选定第8 -9列,存在值大于>20的行
mpg%>%
filter( if_any(8 :9, ~ .x> 20)) %>%
head
3.2 行切片
用 slice_*函数。
参数n,指定要选择的行数
参数prop,按比例选择行
代码演示
# 行切片
mpg%>%
head(n = 10)
mpg %>%
slice( 7: 20) %>%
head
mpg %>%
slice_head(n = 10)
mpg %>%
slice_head(prop = 0. 1)
mpg %>%
slice_tail(n = 10)
mpg %>%
slice_tail(prop = 0. 1)
mpg %>%
slice_sample(n = 10)
# 选择hwy前5大的行
mpg %>%
slice_max(hwy, n = 5)
# 选择hwy前5小的行
mpg %>%
slice_min(hwy, n = 5)
3.3 行删除
用distinct函数删除重复行。
根据所有列或者指定列,判定重复,只保留第1个,其余行删除。
注意:默认只返回选择的列,若要返回所有列, 设置参数.keep_all = TRUE
drop_na函数,删除包含NA的行。
代码演示
# 行删除
# 删除重复行
mpg %>%
distinct
mpg %>%
distinct(drv)
mpg %>%
distinct(drv, .keep_all = TRUE)
mpg %>%
drop_na
3.4 行排序
用arrange函数,对行排序,默认递增。
代码演示
# 行排序
# arrange函数
mpg%>%
arrange(hwy) %>%
head
mpg %>%
arrange(desc(hwy)) %>%
head
mpg %>%
arrange(displ, desc(hwy)) %>%
head
04
聚合操作
聚合操作是指对数据做汇总操作,可以对整个数据框或者对数据框的每个分组。
用 group_by函数创建分组。
访问或者查看分组情况。
代码演示
# 分组group_by函数
iris_group<- iris %>%
group_by(Species)
iris_group
# 了解分组情况
# 分组键值
group_keys(iris_group)
# 查看每一行属于哪一分组
group_indices(iris_group)
# 查看每一组包含那些行
group_rows(iris_group)
# 解除分组
ungroup(iris_group)
其它分组函数
group_split:数据框分割多个分组,返回列表
group_nest:数据框分组,再做嵌套
purrr风格分组迭代,把函数.f依次应用到分组数据框.data的每个分组
代码演示
iris%>%
group_split(Species)
iris %>%
group_nest(Species)
# 提取每组的前两个观察
iris %>%
group_by(Species) %>%
group_map( ~ head(.x,2))
分组汇总
group_by + summarise:对数据框分组,然后做汇总处理。
summarise 与很多自带或自定的汇总函数连用。
代码演示
# 分组汇总
names(iris)
iris %>%
group_by(Species) %>%
summarise(n = n,
Sepal_Length_Mean = mean(Sepal.Length, na.rm = TRUE),
Sepal_Length_Median = median(Sepal.Length, na.rm = TRUE))
summarise 与 across 结合,可以对多列进行操作。
代码演示
# 指定列
iris %>%
group_by(Species) %>%
summarise(across(starts_with( "Sepal"), mean, na.rm = TRUE))
# 所有列
iris %>%
group_by(Species) %>%
summarise(across(everything, mean, na.rm = TRUE))
mpg %>%
group_by( class) %>%
summarise(across(
where( is.numeric),
list(sum=sum, mean=mean),
na.rm = TRUE
))
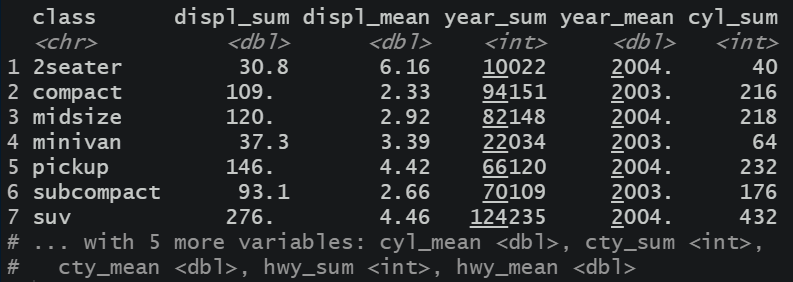
增强可读性,把宽数据表示为长数据。
代码演示
mpg %>%
group_by( class) %>%
summarise(across(
where( is.numeric),
list(sum=sum, mean=mean),
na.rm = TRUE
)) %>%
pivot_longer(- class,
names_to = c( "Vars", ".value"),
names_sep = "_")
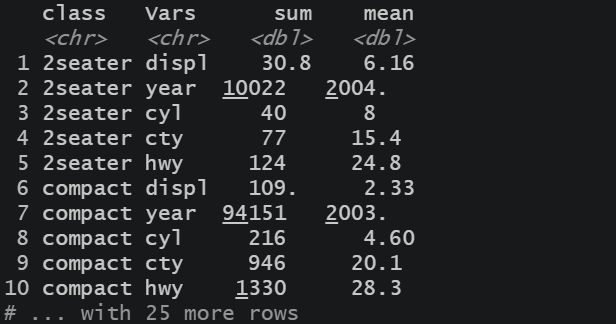
代码演示
qs <- c( 0.25, 0.5, 0.75)
mpg %>%
group_by( class) %>%
summarise(hwy_qs = quantile(hwy, qs, na.rm = TRUE),
q = qs)
# 长变宽
mpg %>%
group_by( class) %>%
summarise(hwy_qs = quantile(hwy, qs, na.rm = TRUE),
q = qs) %>%
pivot_wider(names_from = q, values_from = hwy_qs,
names_prefix = "q_")
# 分组统计
mpg %>%
count( class, sort = TRUE)
mpg %>%
group_by(hwy_level = cut(hwy,
breaks = c( 10, 20, 30, 40, 50),
right = FALSE)) %>%
tally
05
其他操作
排名和排序函数,常用 min_rank函数
代码演示
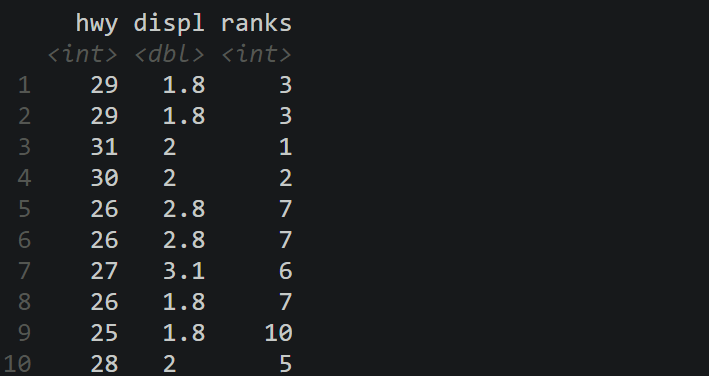
# 常用的min_rank函数
mpg%>%
select(hwy, displ) %>%
slice_head(n = 10)
mpg %>%
select(hwy, displ) %>%
slice_head(n = 10) %>%
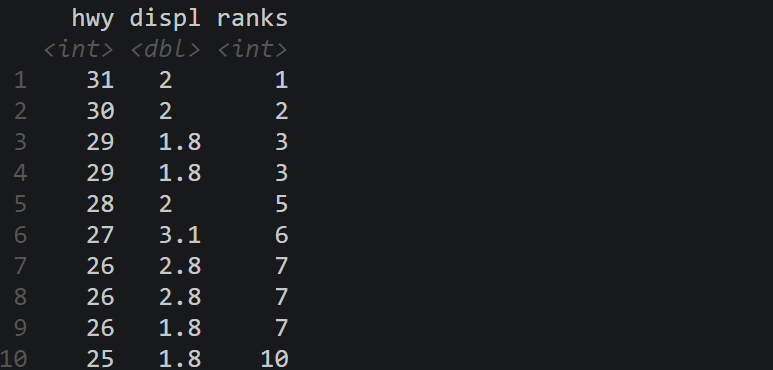
mutate(ranks = min_rank(desc(hwy)))
mpg %>%
select(hwy, displ) %>%
slice_head(n = 10) %>%
mutate(ranks = min_rank(desc(hwy))) %>%
arrange(ranks)
移位函数,lag,向右移位,时间滞后;lead,向左移位,时间超前。
代码演示
library(lubridate)
dt < -tibble(
day= as_date(" 2022-04-01") + c( 0, 4:6),
wday= weekdays(day),
sales= c(2,6,2,3),
balance= c(30,25, -40, 30)
)
dt
# lag时间滞后
dt%> %
mutate(sales_lag = lag(sales),
sales_delta = sales - lag(sales))
# lead时间超前
dt %>%
mutate(sales_lead = lead(sales))
引用与反引用
enquo让函数自动引用参数
!!反引用参数
as_label修改结果列名
代码演示
grouped_mean < -function( data, summary_var, group_var) {
summary_var= enquo(summary_var)
group_var= enquo(group_var)
data%> %
group_by(!!group_var) %>%
summarise(mean = mean(!!summary_var))
}
grouped_mean(mtcars, mpg, cyl)
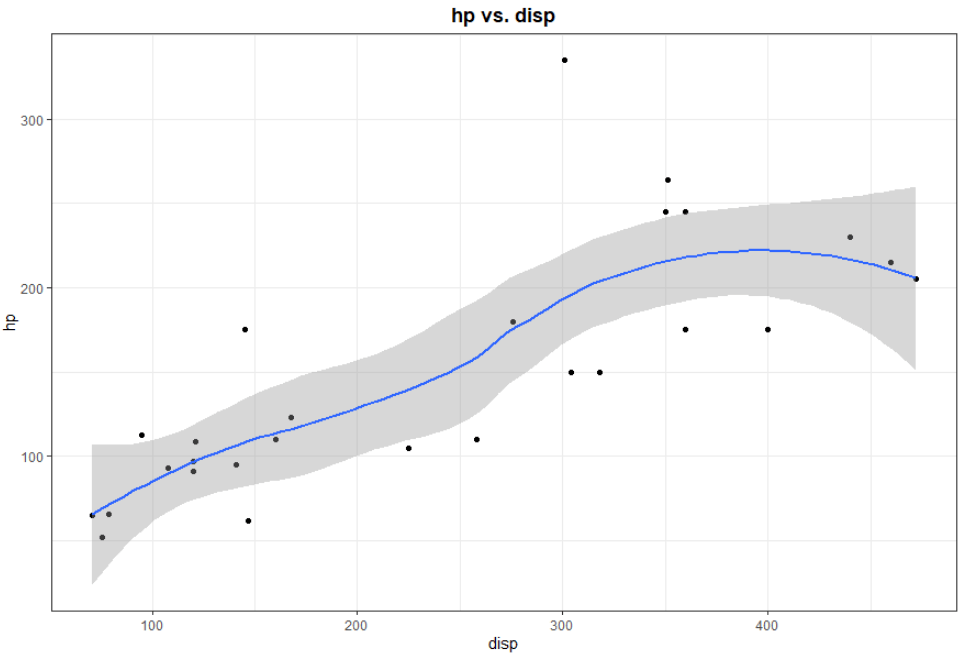
scatter_plot < -function( df, x_var, y_var) {
x_var= enquo(x_var)
y_var= enquo(y_var)
ggplot( data= df,aes( x= !!x_var,y= !!y_var))+
geom_point+
theme_bw+
theme( plot.title= element_text(lineheight= 1,face= "bold", hjust= 0.5))+
geom_smooth+
ggtitle( str_c( as_label( y_var), " vs.", as_label( x_var)))
}
scatter_plot( mtcars, disp, hp)
06
dplyr资料包
为了进一步学习,我准备了一份dplyr资料包。
这个资料包,包括:
1 dplyr包帮助文档,可以当作手册查看
2 dplyr包做数据变换的小手册,常用函数总结
3 dplyr和tidyr包做数据整洁小手册,常用函数总结
4 tidyverse套件做数据操作书籍,有章节总结dplyr包的使用
学习素材:
1https://willhipson.netlify.app/post/dplyr_across/dplyr_across/
2张敬信 (2022). R 语言编程:基于 tidyverse. 人民邮电出版社 , 北京
好了,我写完了。
我提供付费咨询和服务。
你我连接,相互交流,创造更多价值。
—END—
公众号:R语言
作者:王路情