在利用R语言统计分析之前,建议诸位复习数据清洗和整理方法,打好基础!今天,我着重对定量定性数据的转换功能进行总结,并推出tidyverse系列包供大家了解。
1、 数值变量数据转为分类变量数据
数值变量数据经常要转换为分类变量,由于本系列课程分类变量的转换,分散在各处,今天进行汇总。常见的方法如下:
# 先读取数据集
t1<-read.csv("elder1.csv")
t2<-read.csv("elder2.csv")
#第一种方法,利用ifelse进行简单转换
t1$SBP1<-ifelse(t1$SBP>=140,1,0)
#第二种方法,最基本的多分类转换方法
t1$income2[t1$income>=5]<-3
t1$income2[t1$income<5 &t1$income>=3 ]<-2
t1$income2[t1$income<3 ]<-1
# 第三种方法,利用within语句进行
t1<- within(t1,{
income3<-NA
income3[income>=5] <- 3
income3[income<5 & income >=3] <- 2
income3[income < 3] <-1})
#第四种方法,利用循环语句
for(i in 1:length(t1$income)){
if(is.na(t1$income[i])){
t1$income4[i]<-NA
} else if(t1$income[i]<3){
t1$income4[i]<-1
} else if(t1$income[i]<5){
t1$income4[i]<-2
}else if(t1$income[i]>=5){
t1$income4[i]<-3
}
}
# 第五种方法,编一个函数来统筹数据转换
f1<-function(x){
for(i in 1:length(X)){
if(is.na(x[i])){
y[i]<-NA
} else if(x[i]<3){
y[i]<-1
} else if(x[i]<5){
y[i]<-2
}else if(x[i]>=5){
y[i]<-3
}
}
return(y)
}
attach(t1)
t1$income10<-f1(income)
detach
二、分类变量数据因子化和转换
数据库中字符串往往自动默认设置为因子(factor),但是数值型一般默认为numeric。然后,我们数据库构建时,分类数据也会采用数值1、2、3来表达。这个时候,往往需要采用一定的方法进行因子化处理。
常见的方法factor或者as.factor
> is.numeric(t2$sex)
[1] TRUE
> is.factor(t2$sex)
[1] FALSE
> t2$sex<-factor(t2$sex)
> is.factor(t2$sex)
[1] TRUE
我们也可以利用apply族函数来进行因子批量化操作
vars<-c("sex","marriage","education","huji","income","smoking")
t2[vars] <- lapply(t2[vars], factor)
分类数据如何进行转换呢?比如三分类转为二分类,多分类变成二分类。分类数据除了我们第一点“数值变量数据转为分类变量数据”介绍的5种方法之外,还有以下的方法:
#利用dplyr包的mutate语句,可以对factor进行操作,数值结果不形成因子
library(dplyr)
table(t1$income)
t1$income<-factor(t1$income)
t1<-mutate(t1,income5=recode(income,"1"=1,"2"=1,"3"=2))
t1<-mutate(t1,income6=recode(income,"1"=1,"2"=0))
t1<-mutate(t1,income7=recode(income,"1"=1,"2"=0,.default =3) )
is.factor(t1$income7)
#利用dplyr的recode_factor语句,可以对factor进行操作,直接形成因子
s1$income8=recode_factor(t1$income,"1"=1,"2"=2)
s1$income9=recode_factor(t1$income,"1"=1,"2"=2,"3"=2)
table(t1$income)
table(t1$income9)
is.factor(t1$income9)
另外,如果有兴趣者可以学习forcats包来开展因子的处理,这里不再铺开来讲。
三、tidyverse系列包,数据整理当红辣子鸡。
Tidyverse是一组R语言包的集合,看起来似乎我们课程没有介绍过它,但是实际上我们已经接触过它了,学过它的两个包dplyr和tidyr。两个包功能非常强大,给我们留下了深刻印象,但tidyverse不仅包括上述两个包,它还有更多的包。它集合了当下最为流行的数据处理包,是简化数据操纵、便利统计操作、美化结果呈现的高效工具。
有人说,tidyverse系列包,让R语言换发了新的青春!
1. 基本理念
tidyverse是由RStudio首席科学家Hadley Wickham开发的R套装的集。整洁数据是Hadley
等人极力提倡的一个数据处理理念。若要执行统计计算,统计软件对数据格式有一定要求。但通常外部导入的数据并不一定能达到软件处理的要求,而需要进行一定的预处理,此过程通常也称为数据清洗(data
cleaning)。实际上,这种前期处理的工作往往占据比狭义的统计分析更多的时间。为此,需要将无序数据(messy
data)整理成可供计算机程序识别与处理的、具备特定格式的数据,即整洁数据,其基本特征有三:
1.每列为一个变量(Each variable is in a column);
2.每行为一个观测(Each observation is in a row);
3.每个单元格为一个取值(Each value is a cell)。

这些特征在后面的例子中会逐一呈现,这里暂不展开。分析者获得的数据有些本身就适宜软件分析,但很多时候并非如此。使用tidyverse 包,可高效地将无序数据转为整洁数据,以便软件分析。
2.安装与加载
安装tidyverse 包,即可一次性安装多个系列包。

最常用数据分析包:
• ggplot2,用于数据可视化
• dplyr,用于数据操纵
• tidyr,用于数据整洁
• readr,用于读入R 格式数据
• purrr,用于编程
• tibble,用于形成便于数据处理的数据框
数据操纵类:
• stringr,用于处理字符串数据
• lubridate, 用于处理日期和时间数据
• forcats,用于处理因子数据
数据导入类:
• DBI,用于联接数据库
• haven,用于读入SPSS、SAS、Stata 数据
• httr,用于联接网页API
• jsonlite,用于读入JSON 数据
• readxl,用于读入Excel 文档
• rvest,用于网络爬虫
• xml2,用于读入xml 数据
数据建模类:
• modelr,用于使用管道函数建模
• broom,用于统计模型结果的整洁
3.基于tidyverse包的数据整理和加工系统性思维
Hadley 等重新定义了R语言,在他们看来R语言整个流程过于复杂,因此他们在从数据import
到整理、清晰、可视化、建模等多方面都需要得到改善,因此提出清洁R语言的概念。以下两张图说明tidyverse包在数据分析中各个环节中,各包发挥的作用。可以说,我们基于tidyverse
所有的包,就可以完成数据前期整理和清晰的过程,并且可以方便我们更好的构建容易表达的统计模型。
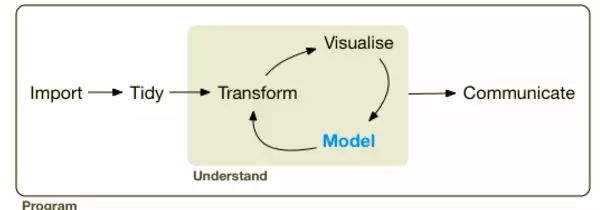
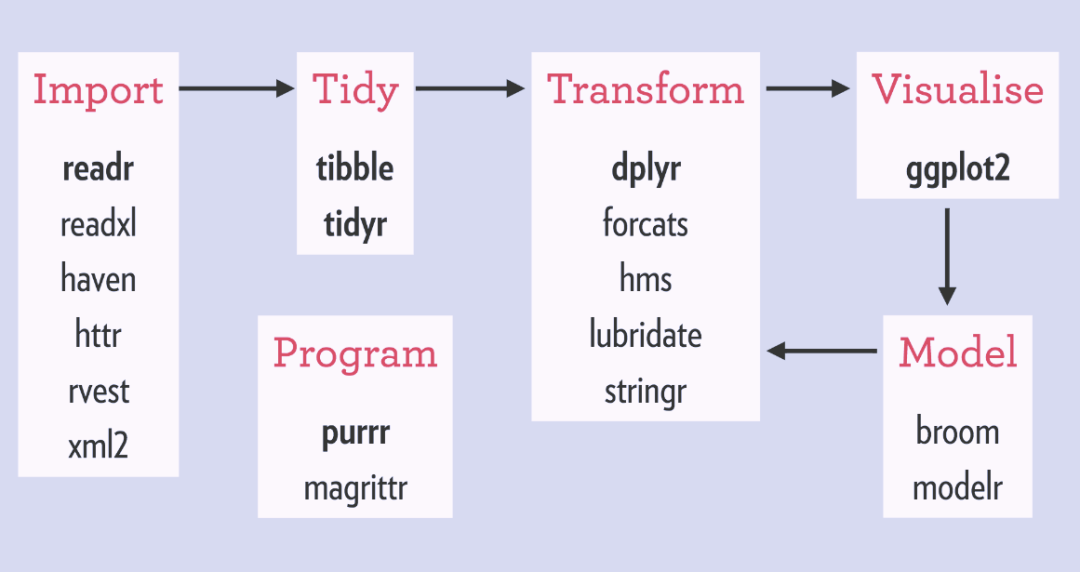
可以看出,tidyverse系列能够在数据整个过程中,不仅是数据整理,在数据导入、可视化、建模、结果表达都能够实现对R编程的重构,简化代码,降低学习和使用R语言的难度。
如果你想深入学习R语言,那么基于tidyverse系统学习R语言是最好的途径!关于tidyverse也有一本专门的书《R for data science》,已经有相应的中文版,这应该是学习tidyverse的一本圣经。
转自:医学论文与统计分析