
在实际工作中,每个数据科学项目各不相同,但基本都遵循一定的通用流程。具体如下:
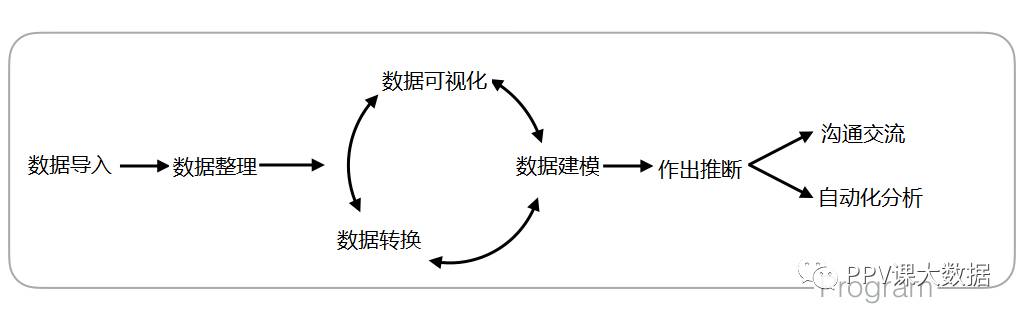
数据科学工作流程
数据导入
数据整理
反复理解数据
数据可视化
数据转换
统计建模
作出推断(比如预测)
沟通交流
自动化分析
程序开发
下面列出每个步骤最有用的一些R包:
数据导入以下R包主要用于数据导入和保存数据
feather:一种快速,轻量级的文件格式。在R和python上都可使用
readr:实现表格数据的快速导入。中文介绍可参考这里
readxl:读取Microsoft Excel电子表格数据
openxlsx:读取Microsoft Excel电子表格数据
googlesheets:读取google电子表格数据
haven:读取SAS,SPSS和Stata统计软件格式的数据
httr:从网站开放的API中读取数据
rvest:网页数据抓取包
xml2:读取HTML和XML格式数据
webreadr:读取常见的Web日志格式数据
DBI:数据库管理系统通用接口包
RMySQL:用于连接MySQL数据库的R包
RPostgres:用于连接PostgreSQL数据库的R包
bigrquery用于连接Google BigQuery的R包
PivotalR:用于读取Pivitol(Greenplum)和HAWQ数据库中的数据
dplyr:提供了一个访问常见数据库的接口
data.table:data.table包的fread()函数可以快速读取大数据集
git2r:用于访问git仓库
数据整理以下R包主要用于数据整理,以便于你后续建模分析:
tidyr:用于整理表格数据的布局
dplyr:用于将多个数据表连接成一个整齐的数据集
purrr:函数式编程工具,在做数据整理时非常有用。
broom:用于将统计模型的结果整理成数据框形式
zoo:定义了一个名zoo的S3类型对象,用于描述规则的和不规则的有序的时间序列数据。
数据可视化以下R包用于数据可视化:
ggplot2及其扩展:ggplot2包提供了一个强大的绘图系统,并实现了以下扩展
ggthemes:提供扩展的图形风格主题
ggmap:提供Google Maps,Open Street Maps等流行的在线地图服务模块
ggiraph:绘制交互式的ggplot图形
ggstance:实现常见图形的横向版本
GGally:绘制散点图矩阵
ggalt:添加额外的坐标轴,geoms等
ggforce:添加额外geoms等
ggrepel:用于避免图形标签重叠
ggraph:用于绘制网络状、树状等特定形状的图形
ggpmisc:光生物学相关扩展
geomnet:绘制网络状图形
ggExtra:绘制图形的边界直方图
gganimate:绘制动画图
plotROC:绘制交互式ROC曲线图
ggspectra:绘制光谱图
ggnetwork:网络状图形的geoms
ggradar:绘制雷达图
ggTimeSeries:时间序列数据可视化
ggtree:树图可视化
ggseas:季节调整工具
lattice:生成栅栏图
rgl:交互式3D绘图
ggvis:交互式图表多功能系统
htmlwidgets:一个专为R语言打造的可视化JS库
leaflet:绘制交互式地图
dygraphs:绘制交互式时间序列图
plotly:交互式绘图包,中文介绍详见这里
rbokeh:用于创建交互式图表和地图,中文介绍
Highcharter:绘制交互式Highcharts图
visNetwork:绘制交互式网状图
networkD3:绘制交互式网状图
d3heatmap:绘制交互式热力图,中文介绍
DT:用于创建交互式表格
threejs:绘制交互式3d图形和地球仪 –rglwidget:绘制交互式3d图形
DiagrammeR:绘制交互式图表
MetricsGraphics:绘制交互式MetricsGraphics图
rCharts:提供了对多个java数据可视化(highcharts/nvd3/polychart)的R封装。
coefplot:可视化统计模型结果
quantmod:可视化金融图表
colorspace:基于HSL的调色板
viridis:Matplotlib viridis调色板
munsell:Munsell调色板
RColorBrewer:图形调色板
igraph:用于网络分析和可视化
latticeExtra:lattice绘图系统扩展包
sp:空间数据工具
数据转换以下R包用于将数据转换为新的数据类型
dplyr:一个用于高效数据清理的R包。视频学习课程
magrittr:一个高效的管道操作工具包。
tibble:高效的显示表格数据的结构
stringr:一个字符串处理工具集
lubridate:用于处理日期时间数据
xts:xts是对时间序列数据(zoo)的一种扩展实现,提供了时间序列的操作接口。
data.table:用于快速处理大数据集
vtreat:一个对预测模型进行变量预处理的工具
stringi:一个快速字符串处理工具
Matrix:著名的稀疏矩阵包
统计建模与推断下述R包是统计建模最常用的几个R包,其中的一些R包适用于多个主题。
car:提供了大量的增强版的拟合和评价回归模型的函数。
Hmisc:提供各种用于数据分析的函数
multcomp:参数模型中的常见线性假设的同时检验和置信区间计算,包括线性、广义线性、线性混合效应和生存模型。
pbkrtest用于线性混合效应模型的参数Bootstrap检验
MatrixModels:用于稠密矩阵和稀疏矩阵建模
mvtnorm:用于计算多元正态分布和t分布的概率,分位数,随机偏差等
SparseM:用于稀疏矩阵的基本线性代数运算
lme4:利用C++矩阵库 Eigen进行线性混合效应模型的计算。
broom:将统计模型结果整理成数据框形式
caret:一个用于解决分类和回归问题的数据训练综合工具包
glmnet:通过极大惩罚似然来拟合广义线性模型
gbm:用于实现随机梯度提升算法
xgboost:全称是eXtreme Gradient Boosting。是Gradient Boosting Machine的一个c++实现。目前已制作了xgboost工具的R语言接口。详见统计之都的一篇介绍
randomForest:提供了用随机森林做回归和分类的函数
ranger:用于随机森林算法的快速实现
h2o:H2O是0xdata的旗舰产品,是一款核心数据分析平台。它的一部分是由R语言编写的,另一部分是由Java和Python语言编写的。用户可以部署H2O的R程序安装包,之后就可以在R语言环境下运行了。
ROCR:通过绘图来可视化分类器的综合性能。
pROC:用于可视化,平滑和对比ROC曲线
沟通交流以下R包用于实现数据科学结果的自动化报告,以便于你跟人们进行沟通交流。
rmarkdown :用于创建可重复性报告和动态文档
knitr:用于在PDF和HTML文档中嵌入R代码块
flexdashboard:基于rmarkdown,可以轻松的创建仪表盘
bookdown:以R Markdown为基础,用于创作书籍和长篇文档
rticles:提供了一套R Markdown模板
tufte:用于实现Tufte讲义风格的R Markdown模板
DT:用于创建交互式的数据表
pixiedust:用于自定义数据表的输出
xtable:用于自定义数据表的输出
highr:用于实现R代码的LaTeX或HTML格式输出
formatR:通过tidy_source函数格式化R代码的输出
yaml:用于实现R数据与YAML格式数据之间的通信。
自动化分析以下R包用于创建自动化分析结果的数据科学产品:
shiny:一个使用R语言开发交互式web应用程序的工具。中文教程
shinydashboard:用于创建交互式仪表盘
shinythemes:给出了Shiny应用程序的常用风格主题
shinyAce:为Shiny应用程序开发者提供Ace代码编辑器。
shinyjs:用于在Shiny应用程序中执行常见的Java操作
miniUI:提供了一个UI小部件,用于在R命令行中集成交互式应用程序
shinyapps.io:为创建的Shiny应用程序提供托管服务
Shiny Server Open Source:为Shiny应用程序提供开源免费的服务器
Shiny Server Pro:为企业级用户提供一个Shiny应用程序服务器
rsconnect:用于将Shiny应用程序部署到shinyapps.io
plumber:用于将R代码转化为一个web API
rmarkdown:用于创建可重复性报告和动态文档
rstudioapi:用于安全地访问RStudio IDE的API
程序开发以下这些包主要用于开发自定义的R包:
RStudio Desktop IDE:R的IDE。大家都懂,不用解释。
RStudio Server Open Source:开源免费的RStudio服务器
RStudio Server Professional:商业版RStudio服务器
devtools:一个让开发R包变得简单的工具集
packrat:创建项目的特定库,用于处理包的版本问题,增强代码重现能力。
drat:一个用于创建和使用备选R包库的工具
testthat:单元测试,让R包稳定、健壮,减少升级的痛苦。
roxygen2:通过注释的方式,生成文档,远离Latex的烦恼。
purrr:一个用于 提供函数式编程方法的工具
profvis:用于可视化R代码的性能分析数据
Rcpp:用于实现R与C++的无缝整合。详见统计之都文章
R6:R6是R语言的一个面向对象的R包,可以更加高效的构建面向对象系统。
htmltools:用于生成HTML格式输出
nloptr:提供了一个NLopt非线性优化库的接口
minqa:一个二次近似的优化算法包
rngtools:一个用于处理随机数生成器的实用工具
NMF:提供了一个执行非负矩阵分解的算法和框架
crayon:用于在输出终端添加颜色
RJSONIO:rjson是一个R语言与json进行转的包,是一个非常简单的包,支持用 C类库转型和R语言本身转型两种方式。
jsonlite:用于实现R语言与json数据格式之间的转化
RcppArmadillo:提供了一个Armadillo C++ Library(一种C++的线性代数库)的接口
实验数据以下R包给出了案例实战过程中可用的训练数据集:
babynames:包含由美国社会保障局提供的三个数据集
neiss:2009-2014年期间提供给美国急诊室的所有事故报告样本数据
yrbss:美国疾病控制中心2009-2013年期间青年危险行为监测系统数据
hflights:
USAboundaries:2011年全年休斯顿机场的所有航班数据
rworldmap:国家边界数据
usdanutrients:美国农业部营养数据库
fueleconomy:美国环保署1984-2015年期间的燃油经济数据
nasaweather:包含了一个覆盖中美洲的非常粗糙的24*24格地理位置和大气测量数据。
mexico-mortality:墨西哥死亡人数数据
data-movies和ggplotmovies:来自互联网电影数据库imdb.com的数据
pop-flows:2008年全美人口流动数据
data-housing-crisis:经过清洗后的2008美国房地产危机数据
gun-sales:纽约时报提供的有关枪支购买的每月背景调查统计分析数据
stationaRy:从成千上万个全球站点收集到的每小时气象数据
gapminder:摘自Gapminder的数据
janeaustenr:简·奥斯丁小说全集数据
更多R包介绍查看CRAN任务视图
参考文章
RStartHere
http://blog.fens.me/