一、更改主机名与映射、添加用户
1. 修改/etc/hostname ,删除文件内容, 重新输入名字 ,例如master
2.修改/etc/sysconfig/network ,添加 NETWORKING=yes 与 HOSTNAME=master
可以使用SHELL脚本执行
echo "slave2" > /etc/hostname
echo "NETWORKING=yes" >> /etc/sysconfig/network
echo "HOSTNAME=slave2" >> /etc/sysconfig/network
记住更改 红色标记处
需要进行重启操作
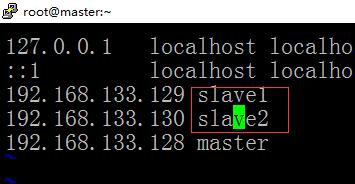
3.配置映射
修改 /etc/hosts文件,不用清空文件内容
记得单词要敲对
4. 创建用户

二、上传文件与配置
1.上传HADOOP与JDK文件
2.解压文件
tar -zxvf hadoop.tar.gz -C /opt
tar -zxvf jdk.tar.gz -C /opt
3.配置环境变量
echo "export JAVA_HOME=/opt/jdk1.8" >> /etc/profile
echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin' >> /etc/profile
source /etc/profile
4.关闭防火墙-ROOT用户
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #防火墙失效
systemctl status firewalld #查看防火墙状态
三、配置HADOOP文件
手动创建目录/opt/hadoop/tmp
修改的主要
两个SH,四个XML,一个salves
SH分别为 HADOOP-ENV.SH YARN-ENV.SH
XML为: core hdfs mapred yarn
1. 修改yarn-env.sh文件
进入vi /opt/hadoop/etc/hadoop/yarn-env.sh
找到:export HADOOP_YARN_USER=${HADOOP_YARN_USER:-yarn}
修改为:export HADOOP_YARN_USER=/opt/hadoop
2. core-site.xml
因为单机版已经配置过,所以只需要修改主机名就可以了
进入:vi /opt/hadoop/etc/hadoop/core-site.xml
修改为自己的主机名:
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
3. 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
</configuration>
4. 修改mapred-site.xml
操作以前将mapred-site.xml.template复制一个名为mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
加入以下代码:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> master:19888</value>
</property>
</configuration>
5. 修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
修改SLAVES文件
内容为:
slave1
slave2
四、配置互信
1. 主机端生成公钥与密钥
ssh-keygen -t rsa -P ‘’
然后一直回车直到生成密钥
执行完成过后,会在该用户的主工作目录下生成 .ssh ,并且文件中包含 id_rsa id_rsa.pub两个文件
2. 从机生成公钥与密钥
ssh-keygen -t rsa -P ‘’
然后从机将自己的 pub 公钥 复制给 主机
命令如下
Scp -r .ssh/id_rsa.pub hadoop@master:/home/hadoop/id_rsa_01.pub
Scp -r .ssh/id_rsa.pub hadoop@master:/home/hadoop/id_rsa_02.pub
3. 把从机的公钥追加到主节点的authorized_keys
命令如下:
cat id_rsa_01.pub >> .ssh/authorized_keys
cat id_rsa_02.pub >> .ssh/authorized_keys
4. 把主机自己的公钥同样追加到 authorized_keys
5. 在每台机器上面执行
前提条件:必须位于用户的主工作目录
chmod 600 .ssh/authorized_keys
验证方法: master 切 slave1 master 切 slave2
slave1 切 slave2
slave1 切 master
slave2 切 slave1
slave2 切 masters
五、HADOOP用户授权(OPT)
拷贝主节点的JDK与 HADOOP文件到各从机,HADOOP用户
命令如下:
Scp -r /opt/jdk hadoop@slave1:/opt/
Scp -r /opt/jdk hadoop@slave2:/opt/
Scp -r /opt/hadoop hadoop@slave2:/opt/
Scp -r /opt/hadoop hadoop@slave1:/opt/
复制完成过后执行配置环境变量
echo "export JAVA_HOME=/opt/jdk1.8" >> /etc/profile
echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin' >> /etc/profile
source /etc/profile
因为HADOOP或者 JDK 都是由ROOT上传
但是启动又是HADOOP用户启动,所以HADOOP用户必须持有 /OPT下的操作权限
每台机器
执行用户:ROOT
执行命名:chown -R hadoop:hadoop /opt
六、启动与验证
1. NAMENODE的FORMAT
命令如下: hadoop namenode -format
中途出现错误: 目录不存在,或者不能创建
原因是:因为HADOOP用户没有权限操作TMP
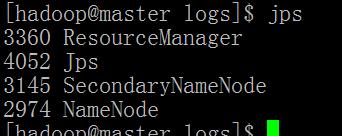
2. 启动HDFS
命令如下
$HADOOP_HOME/sbin/start-dfs.sh
如果中途出现错误:可以直接定位日志 /opt/hadoop/logs
Logs下面存在多种角色的启动日志,查看启动失败角色的日志
缺少哪一个看哪一个
3. 验证HDFS
方法1:上传文件
命令如下:(上传HADOOP的HDFS启动日志文件)
Hadoop fs -put /file /file
方法2:远程访问界面
DATANODES有两个
4. 启动YARN
脚本如下:$HADOOP_HOME/sbin/start-yarn.sh
主要角色有RESOURCE MANAGER
从角色:NODEMANAGER
5. 验证YARN
页面:Http://master:8088,能够看到小象
作业:
hadoop jar
/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar
wordcount /hadoop-hadoop-namenode-master.log /out
红色标记的文件需要自己上传到 hdfs
最后两个参数代表,要分析的输入文件与分析结果的输出文件
输出文件包含两个:一个_SUCCESS 一个结果文件
@来自科多大数据高级构架师张旭,转载须注明出处