作者简介
野菜团子,R语言中文社区专栏作者
博客:https://ask.hellobi.com/blog/esperanca
forcats包用于处理因子,可以更高效地对因子进行修改。
1. 生成因子
R语言的base包中函数如dataframe等默认因子在分类变量读入时就会生成,而tidyverse包中的readr等包则会保留数据读入时的原样不做改变,要生成因子则可以使用parse_factor函数进行处理。parse_factor函数更审慎一些,会对不在给定的因子水平中的变量取值一个警告,而base包中的factor则会直接将该值记为NA,不给出报错或警告。
x <- c("Dec", "Apr","Jam", "Mar")
month_levels <- c(
"Jan", "Feb", "Mar","Apr", "May", "Jun", "Jul","Aug", "Sep", "Oct", "Nov","Dec"
)
y <- parse_factor(x, levels = month_levels)
如下图,x中的“Jam”不在给定的因子水平中,所以返回一个警告。

2. 因子调序
实践中经常需要对因子进行重新排序,比如为了绘制的图形更美观等目的。fct_reorder函数即用于此。它可以将因子按照给定的数字向量进行调整。
以美国综合社会调查的数据gss_cat为例,它有9个变量,21483个观测值。我们想要绘制人口中不同宗教信仰的人每天看电视的时间的均值图:
relig <- gss_cat %>%
group_by(relig) %>%
summarize(
age = mean(age, na.rm = TRUE),
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)
ggplot(relig, aes(tvhours, relig)) + geom_point()
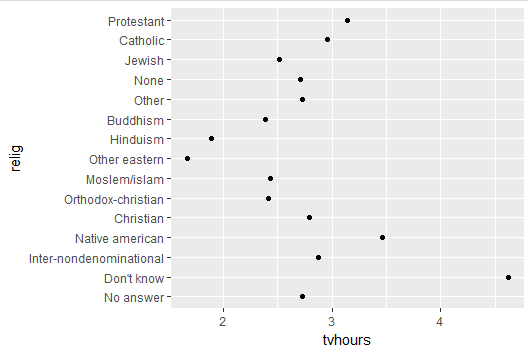
各宗教的排序散乱,我们想要宗教的顺序按照看电视的时间递减排序,就可以把tvhours作为排序的参数进行调整,再传入ggplot函数中作为纵轴:
ggplot(relig, aes(tvhours, fct_reorder(relig,tvhours))) +
geom_point()
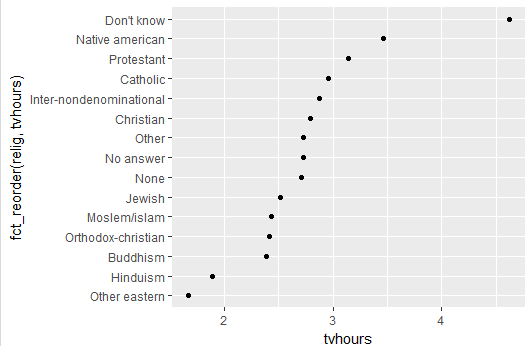
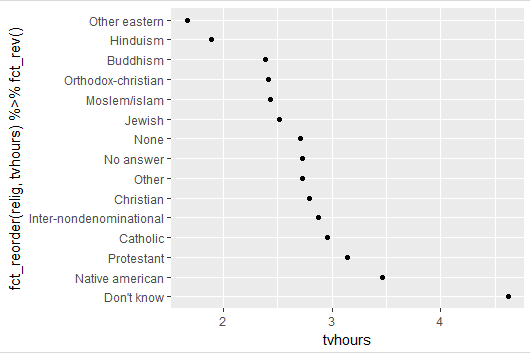
如果想要递增排序,就再加上一个fct_rev函数:
ggplot(relig, aes(tvhours, fct_reorder(relig, tvhours)%>% fct_rev())) +
geom_point()
3. 修改因子水平
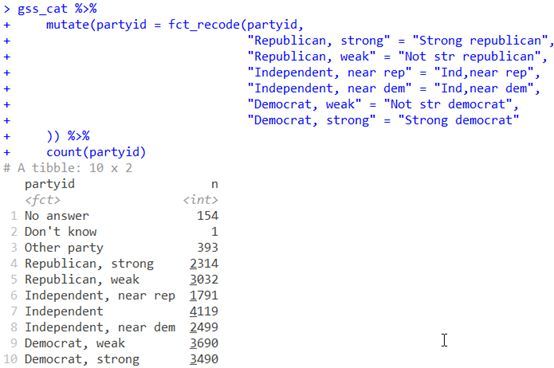
有的数据中的因子水平表述不清,我们需要将它们重新命名。这时候fct_recode函数就派上了用场。比如gss_cat数据中,记录的人们的政治倾向中,我们想把"Strongrepublican"改为"Republican,
strong"、"Not str republican"改为"Republican,weak",等等:
gss_cat %>% count(partyid)
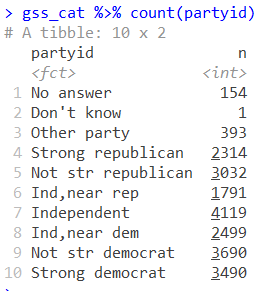
gss_cat %>%
mutate(partyid = fct_recode(partyid,
"Republican, strong" = "Strongrepublican",
"Republican, weak" = "Not strrepublican",
"Independent, near rep" = "Ind,nearrep",
"Independent, near dem" = "Ind,neardem",
"Democrat, weak" = "Not strdemocrat",
"Democrat, strong" = "Strongdemocrat"
)) %>%
count(partyid)
进一步观察我们发现,partyid中有"Noanswer", "Don't
know", "Other
party"的记录,这样的细分没有太大意义,我们可以将它们全部改为"Other",同样的,如果我们不在意他们是否是坚定的拥护者,只想知道他们的党派立场,还可以重新归纳为共和党、民主党、中立三个因子。这一任务用fct_recode函数可以实现,只要把它们都重命名为"Other"就可以。但是太过繁琐,我们可以使用fct_collapse函数:
gss_cat %>%
mutate(partyid = fct_collapse(partyid,
other = c("No answer", "Don'tknow", "Other party"),
rep = c("Strong republican", "Notstr republican"),
ind = c("Ind,near rep","Independent", "Ind,near dem"),
dem = c("Not str democrat", "Strongdemocrat")
) ) %>%
count(partyid)

如果以上的归类还是嫌很麻烦,想要将占比很小的一些分类自动归为一类,可以使用fct_lump函数,参数n表示想要保留的总类别的数目。例如我想要把宗教的分类只保留10个:
gss_cat %>%
mutate(relig = fct_lump(relig, n = 10)) %>%
count(relig, sort = TRUE)
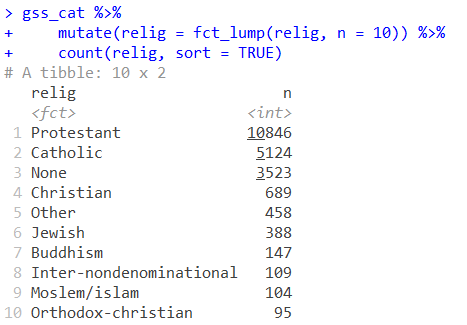
如上图,原本从Orthodox到christian的分类都重新划归到Orthodox-christian这一类中了
转自:R语言中文社区