这一周R语言学习,记录如下。
01
添加文本标签信息
可视化时,通过文本标签对图形做标注,让图形更有效表达信息。以ggplot2包的条形图为例,使用geom_text()函数给条形图添加文本标签。
library(ggplot2)
set.seed( 123)
data<- data.frame(x = sample(LETTERS[ 1: 6], 300, replace= TRUE))
head( data)
dim( data)
# 使用geom_text()函数
ggplot( data, aes(x = factor(x), fill = factor(x))) +
geom_bar() +
geom_text(aes(label = ..count..),
stat = "count",
vjust = 1.5,
colour = "white")
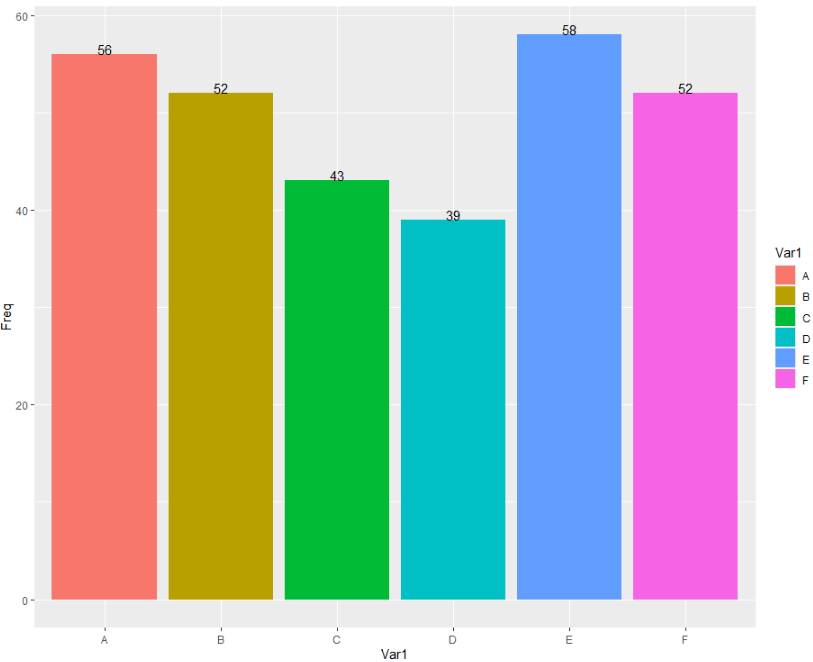
# 或者
data1<- as.data.frame( table( data$x))
data1
ggplot(data1, aes(x = Var1, y = Freq, fill = Var1)) +
geom_bar(stat = "identity") +
geom_text(aes(label = Freq),
vjust = 0)
结果图
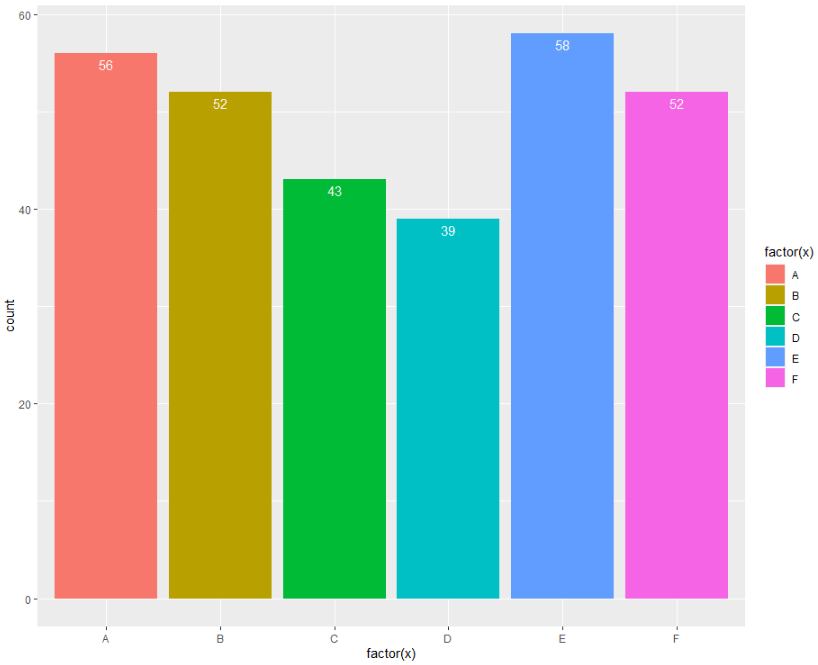
02
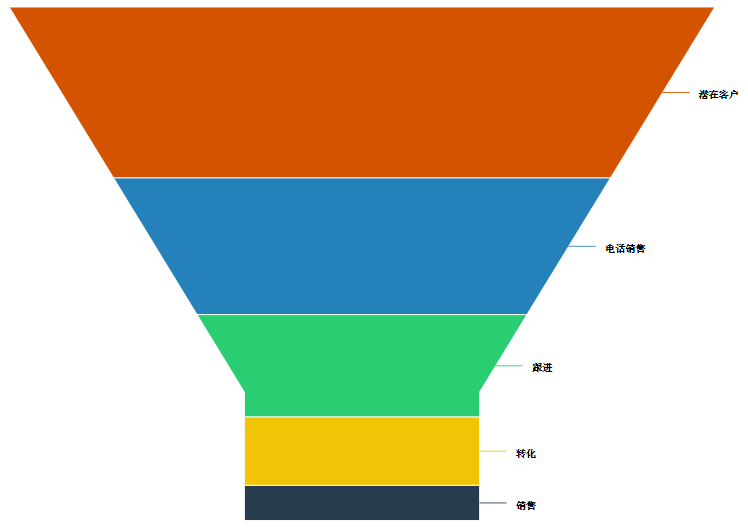
漏斗图
漏斗图适合于流转分析。
比方说,信贷流程:申请--审批--授信--放款;电商购物流程:浏览--点击--加入购物车--付款。
library(dplyr)
library(highcharter)
options(highcharter.theme = hc_theme_smpl(tooltip = list(valueDecimals = 2)))
df <- data.frame(
x = c( 0, 1, 2, 3, 4),
y = c( 975, 779, 584, 390, 200),
name = as.factor(c( "潜在客户", "电话销售", "跟进", "转化", "销售"))
) %>%
arrange(-y)
(df)
hc <- df %>%
hchart(
"funnel",
hcaes(x = name, y = y),
name = "销售流转"
)
hc
结果图
03
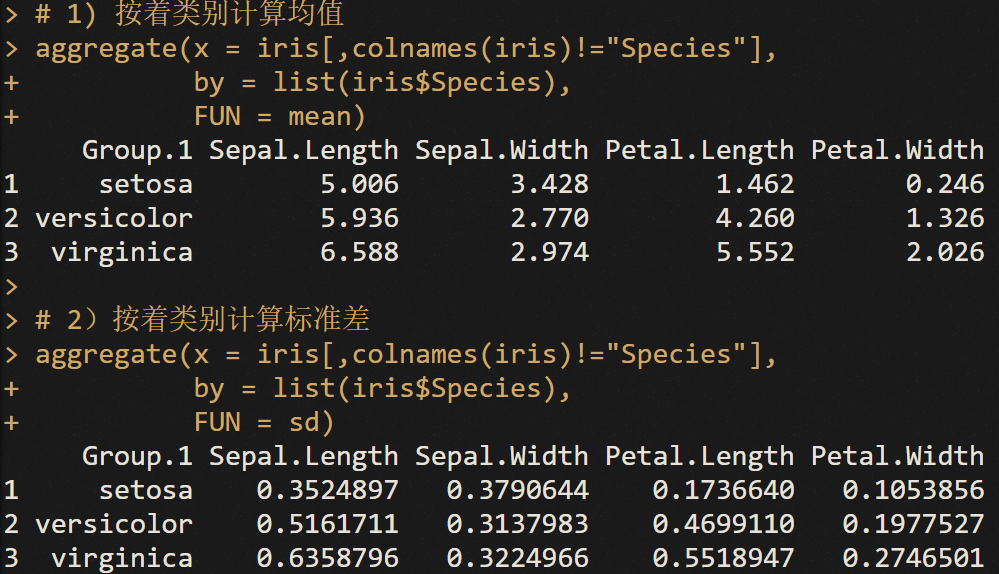
聚合函数aggregate
聚合函数aggregate对数据框做汇总操作。
函数用法
举例说明
# 聚合函数aggregate对数据框做汇总操作
help( "aggregate")
data(iris)
# 1) 按着类别计算均值
aggregate(x = iris[,colnames(iris)!= "Species"],
by= list(iris$Species),
FUN = mean)
# 2)按着类别计算标准差
aggregate(x = iris[,colnames(iris)!= "Species"],
by= list(iris$Species),
FUN = sd)
04
帕累托图
二八法则
帕累托图,条形图和折线图的结合体。
条形图,表示各个类别的频数;折线图,表示各个类别的累积占比,具有排序性。
library(qcc)
df <- data.frame(product=c( 'A', 'B', 'C', 'D', 'E', 'F'),
count=c( 40, 57, 50, 82, 17, 16))
df
pareto.chart(df$count,
main= 'Pareto Chart',
col=heat.colors( length(df$count)))
结果表
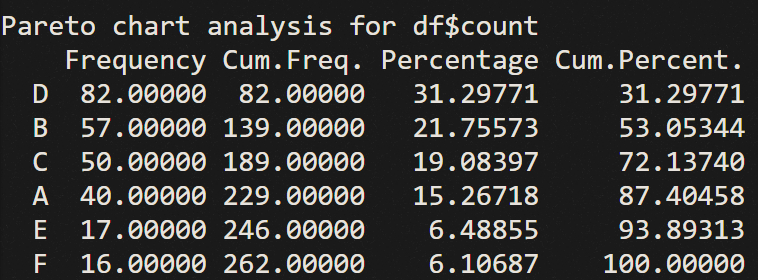
结果图
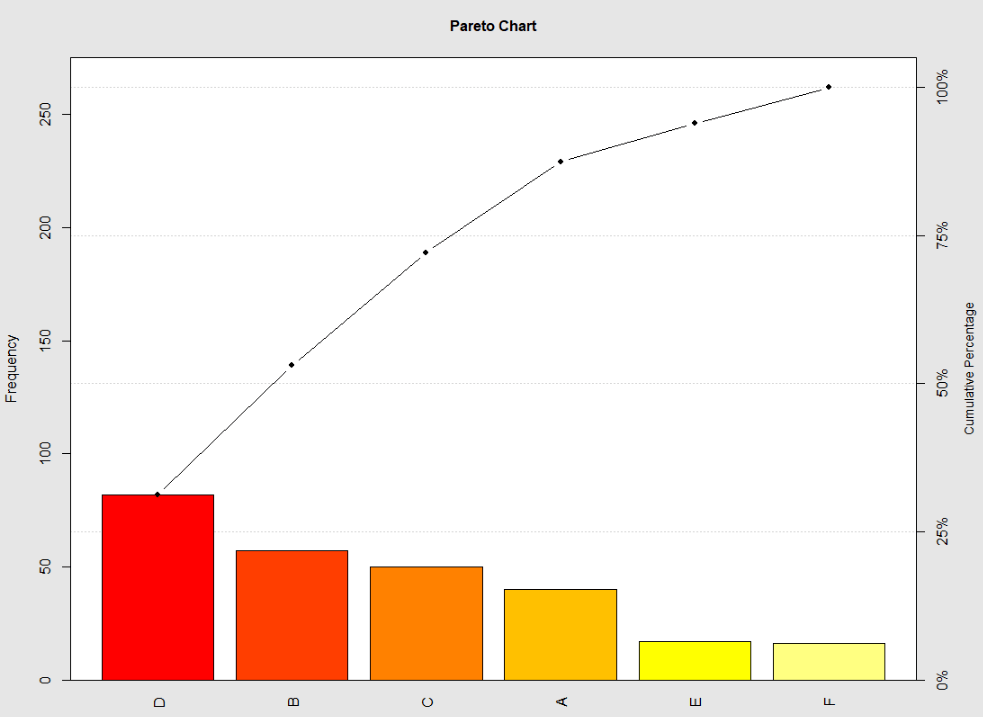
05
探索性数据分析
原始数据入手,采用数字化和可视化方式,对数据做探索性分析
助于对数据的理解和认识
基本思路:通过汇总统计和图形表示,以发现模式、异常和检验假设
# R包
library(tidyverse)
library(DataExplorer)
# 数据集
dim(gss_cat)
str(gss_cat)
# 1) 数据集概览
gss_cat %>% glimpse()
# 2) 数据集简要
gss_cat %>% introduce()
# 3) 数据简要信息可视化
gss_cat %>% plot_intro()
# 4) 变量缺失率分析
gss_cat %>% plot_missing()
gss_cat %>% profile_missing()
# 5) 连续变量可视化
gss_cat %>% plot_density() # 密度曲线图
gss_cat %>% plot_histogram() # 直方图
# 6) 类别变量可视化
gss_cat %>% plot_bar() # 条形图
# 7) 相关性可视化图
gss_cat %>% plot_correlation()
gss_cat %>% plot_correlation(maxcat = 5)
# 8) 探索性分析报告
gss_cat %>%
create_report(
output_file = "gss_survey_data_profile_report",
output_dir = "./report/",
y= "rincome",
report_title = "EDA Report"
)
部分结果图
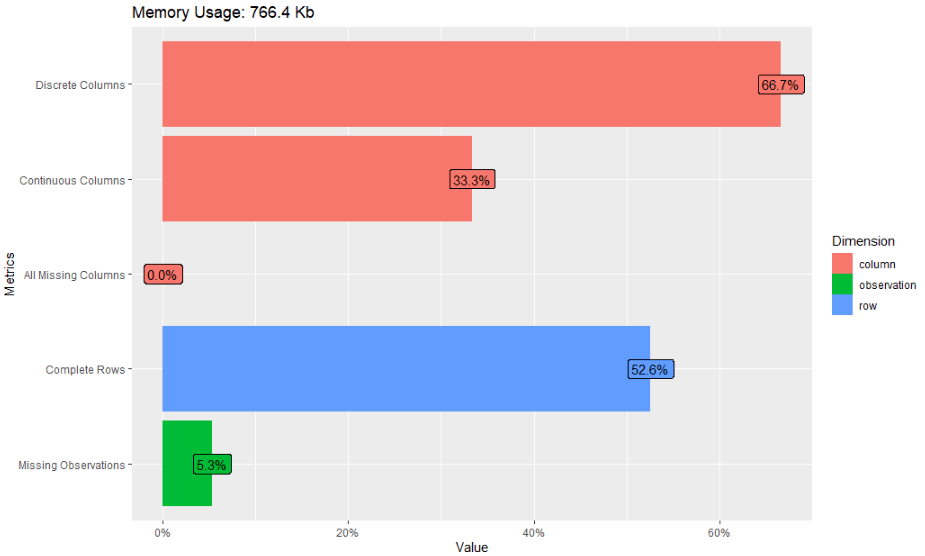
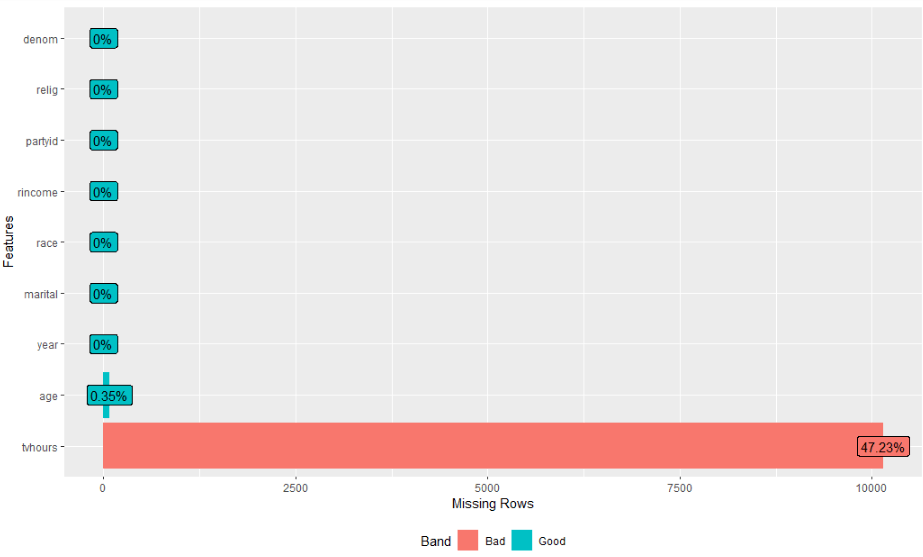
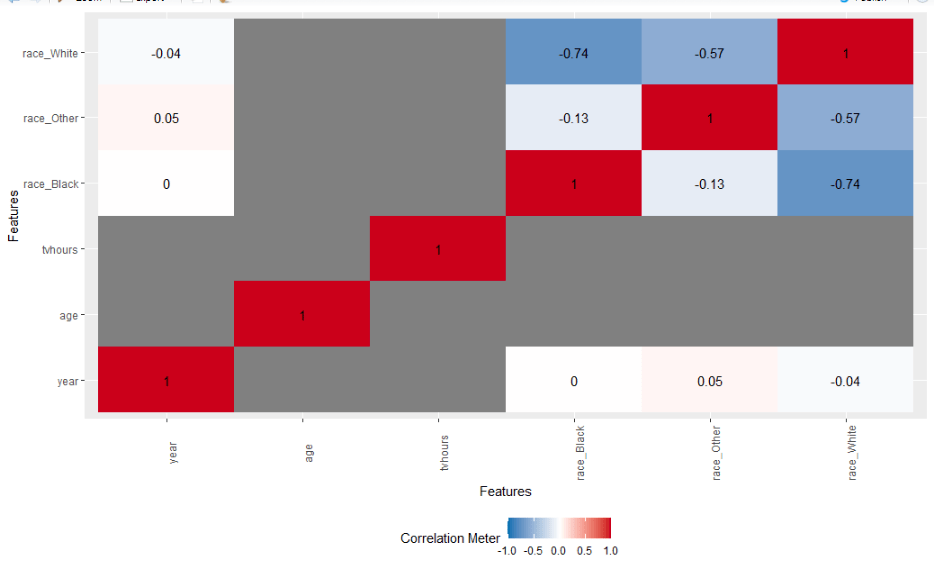
(完整结果,请运行代码自测)
06
雷达图
雷达图,又叫蜘蛛图,用于可视化多个定量变量的值,实现多个变量在二维空间的对比分析。
客户分群项目,总结每个群体的特性时,可以用雷达图来表示。
library(tidyverse)
# devtools::install_github("ricardo-bion/ggradar")
library( "ggradar")
data<- data.frame(
row.names = c( "A", "B", "C"),
Thickness = c( 7.9, 3.9, 9.4),
Apperance = c( 10, 7, 5),
Spredability = c( 3.7, 6, 2.5),
Likeability = c( 8.7, 6, 4)
)
data
df <- data %>% rownames_to_column( "group")
df
ggradar(
df,
values.radar = c( "0", "5", "10"),
grid.min = 0,
grid. mid= 5,
grid.max = 10,
# Polygons
group.line.width = 1,
group.point.size = 3,
group.colours = c( "#00AFBB", "#E7B800", "#FC4E07"),
background.circle.colour = "white",
gridline. mid.colour = "grey",
legend.position = "bottom"
)
结果图
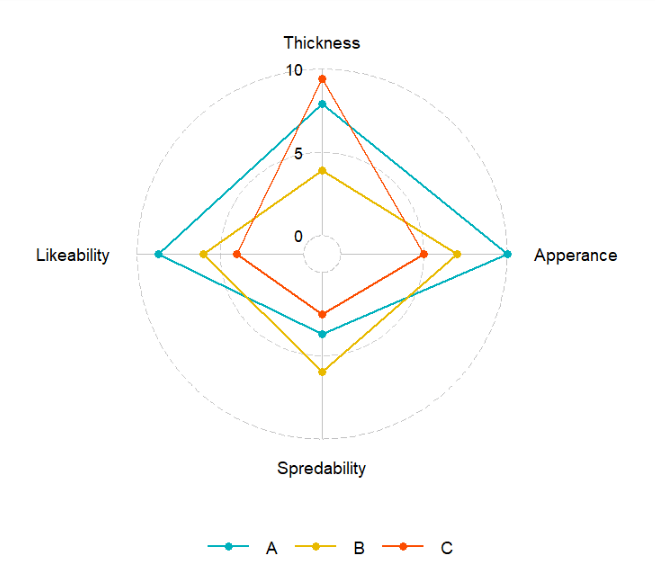
07
可重复性代码构建指南
创建项目工程,做项目管理
项目的层级架构,参考下图:
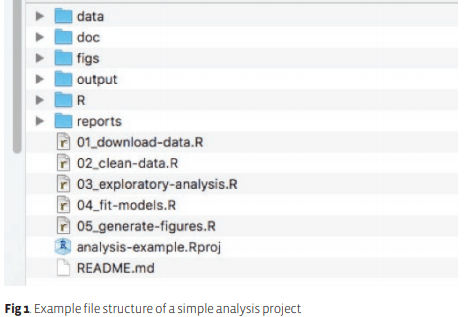
各个文件夹和文件的用途

请注意
1 永远不要修改原始数据,或者说,一定要备份好原始数据
2 对于任何项目,创建一个文件,记录你的所思和所做,便于复盘和迭代
3 脚本的命名,请知名晓意,赋予含义,具有条理性和逻辑性,重视代码的可读性,代码是让电脑来运行的,更重要的是,让人来看的。
4 对于一个复杂的项目,编写代码之前,先写伪代码或者画流程图
08
tidyverse技能增进
tidyverse是数据科学套件包,也是我常用的R包,可以完成数据导入、探索性数据分析、数据处理和整理、统计分析等数据工作。
如何提升tidyverse技能?
多学它和多用它。
本周发现了一本tidyverse技能的线上书籍,送给大家。
访问网址:
https://jhudatascience.org/tidyversecourse/
本书在开篇,就谈到了数据科学生命周期,一起学习下,关键的地方我做了标注。

关于tidyverse包,有什么问题或者想法,可以添加我的微信,入群一起讨论和交流。
09
TidyX项目
项目愿景:通过做一系列有趣、有用、好玩的数据项目,帮助更多人学习和应用R,以及从数据中学习和用数据解答问题。
项目内容:从TidyTuesday项目中选择一个人的代码,逐行阅读代码,解析代码是做什么以及各函数的功能,拆分可视化和迁移到相似的应用场景。
第一集:研究旧金山数据集的代码
源代码
# 读入数据
# sf_trees <-
readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-01-28/sf_trees.csv')
sf_trees <- readr::read_csv( './data/tidytuesday/data/2020/2020-01-28/sf_trees.csv')
# 探索数据
# 提取类别名
# Extract specie name
library(stringr)
species <- as.data.frame( as.character(word(sf_trees$species, 1, 2)))
names(species)[ 1] <- "specie"
sf_trees <-
cbind(sf_trees, species) #Bind specie name with datase
sf_trees$specie <-
gsub( "[[:punct:]]", " ", sf_trees$specie) #Remove punctuation
# Extract trees planted last year
# 获取数据集
sf_trees$year<- as.numeric(substr(sf_trees$date, start = 1, stop = 4)) #Get year
trees2010s <-subset(sf_trees, year >= 2015& year <= 2019)
# 可视化
# 生成树地图
#Get specie planted by year
library(dplyr)
count <- trees2010s %>%
group_by(specie, year) %>%
count()
# Remove empty rows
count <- count[-c( 509: 513, 544: 548), ]
# Generate treemap
library(treemap)
treemap<-treemap(count,
index=c( "year", "specie"),
vSize= "n",
type= "index",
title= "Trees Planted in San Francisco\n 2015-2019",
fontsize.title = 14,
fontsize.labels=c( 15, 11),
fontcolor.labels=c( "black", "brown"),
fontface.labels=c( 2, 2),
overlap.labels= 1,
inflate.labels=F,
palette= "Greens",
align.labels= list(
c( "right", "bottom"),
c( "center", "center")))
结果图
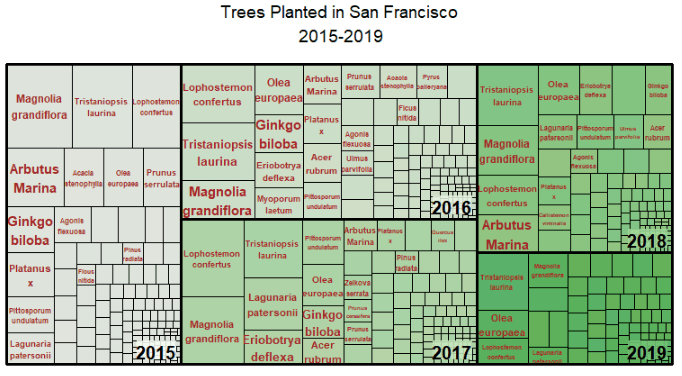
读代码
1 数据读取,采用readr包的read_csv函数。若是不能在线读取,就先进入githhub,把tidytuesday项目克隆一份到本地
执行命令:
git clone https://github.com/rfordatascience/tidytuesday.git
若是不能打开github,就添加前面我的微信,备注:姓名-tidytuesday,我把下载好的本地化数据分享给你。
2 字符串处理,利用stringr包的函数做字符串处理
3 聚合统计,利用dplyr包的groupby函数和聚合函数count()做分组统计
4 画树地图,利用treemap包的treemap函数绘制树地图。
说明:1-3中的包已经包含在tidyverse包里面,treemap包使用前先安装和加载好。
学习资料:
https://github.com/CourtneyGerver/tidytuesday/blob/master/Week05-SFtrees/sfTreeViz.R