Tidyverse| XX_join :多个数据表(文件)之间的各种连接
2022-8-20 萌小白
前面分享了单个文件中的select列,filter行,列拆分等,实际中经常是多个数据表,综合使用才能回答你所感兴趣的问题。
一 载入数据,R包
library(tidyverse) x <- tribble( ~key, ~val_x, 1, "x1", 2, "x2", 3, "x3" ) y <- tribble( ~key, ~val_y, 1, "y1", 2, "y2", 4, "y3" )
二 合并数据
向数据框中加入新变量,新变量的值是另一个数据框中的匹配观测。
1 连接方式
1) 内连接 inner_join
内连接是最简单的一种连接,只要两个观测的键是相等的,即可匹配。
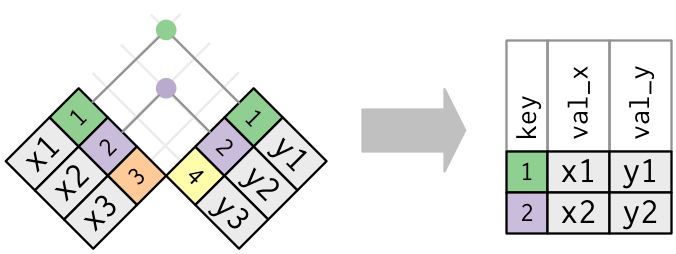
注释:匹配在实际的连接操作中是用圆点表示的。圆点的数量 = 匹配的数量 = 结果中行的数量。下同
x %>% inner_join(y, by = "key") # A tibble: 2 x 3 key val_x val_y <dbl> <chr> <chr> 1 1 x1 y1 2 2 x2 y2
内连接最重要的性质是,没有匹配的行不会包含在结果中。容易丢失观测,慎用。
2) 外连接
外连接则保留至少存在于一个表中的观测。外连接有 3 种类型: • 左连接 left_join:保留 x 中的所有观测。 • 右连接 right_join:保留 y 中的所有观测 • 全连接 full_join:保留 x 和 y 中的所有观测。
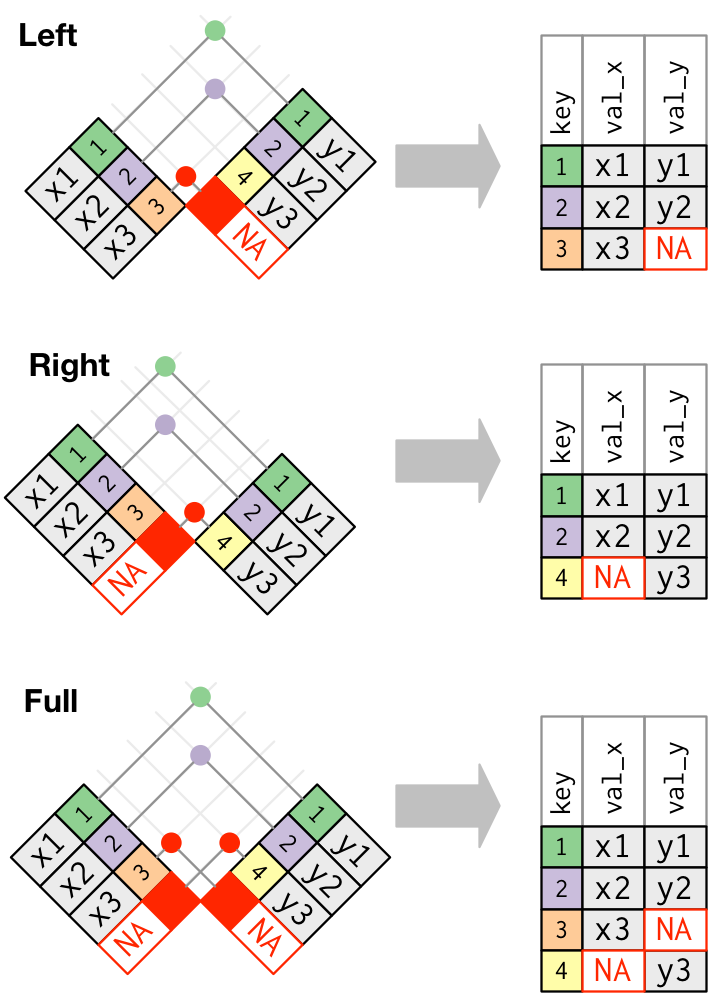
x %>% left_join(y, by = "key") # A tibble: 3 x 3 key val_x val_y <dbl> <chr> <chr> 1 1 x1 y1 2 2 x2 y2 3 3 x3 <NA> x %>% right_join(y, by = "key") # A tibble: 3 x 3 key val_x val_y <dbl> <chr> <chr> 1 1 x1 y1 2 2 x2 y2 3 4 <NA> y3 x %>% full_join(y, by = "key") # A tibble: 4 x 3 key val_x val_y <dbl> <chr> <chr> 1 1 x1 y1 2 2 x2 y2 3 3 x3 <NA> 4 4 <NA> y3
2 重复键
以上均假设键具有唯一性,但情况并非总是如此。
如果x中的key变量,在y中有多个同样的key,那么所有的结合可能都会罗列出来
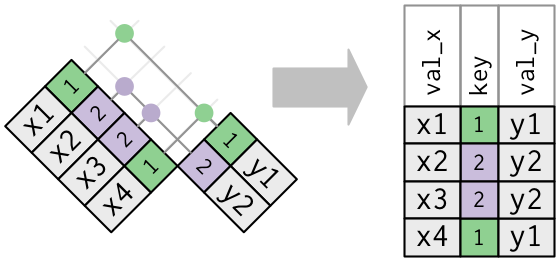
x1 <- tribble( ~key, ~val_x, 1, "x1", 2, "x2", 2, "x3", 1, "x4" ) y1 <- tribble( ~key, ~val_y, 1, "y1", 2, "y2" ) left_join(x1, y1, by = "key") # A tibble: 4 x 3 key val_x val_y <dbl> <chr> <chr> 1 1 x1 y1 2 2 x2 y2 3 2 x3 y2 4 1 x4 y1
3 定义连接键
1) 默认值 by = NULL
使用存在于两个表中的所有变量,这种方式称为自然连接。
left_join(x, y) Joining, by = "key" # A tibble: 3 x 3 key val_x val_y <dbl> <chr> <chr> 1 1 x1 y1 2 2 x2 y2 3 3 x3 <NA>
2) 定义匹配键 by = c("a" = "b")
匹配 x 表中的 a 变量和 y 表中的 b 变量,输出结果中使用的是 x 表中的变量。
y_1 <- tribble( ~key2, ~val_y, 1, "y1", 2, "y2" ) left_join(x, y_1, by = c("key" = "key2")) # A tibble: 3 x 3 key val_x val_y <dbl> <chr> <chr> 1 1 x1 y1 2 2 x2 y2 3 3 x3 <NA>
3) 多个匹配键
x2 <- tribble( ~key,~key1, ~val_x, 1, 2018,"x1", 2, 2019,"x2", 3, 2019,"x3" ) y2 <- tribble( ~key, ~key1,~val_y, 1, 2018,"y1", 2, 2018,"y2", 4, 2019,"y3" ) inner_join(x2,y2,by = c("key","key1")) # A tibble: 1 x 4 key key1 val_x val_y <dbl> <dbl> <chr> <chr> 1 1 2018 x1 y1
三 筛选连接
筛选连接匹配观测的方式与合并连接相同,但前者影响的是观测,而不是变量。筛选连接 有两种类型。
semi_join函数
保留 x 表中与 y 表中的观测相匹配的所有观测
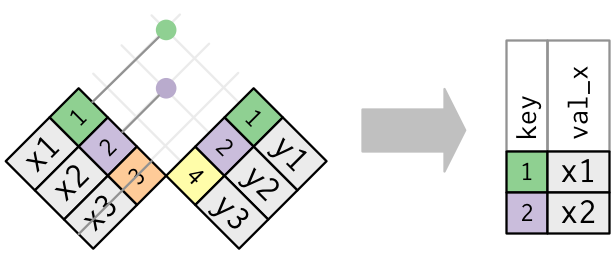
semi_join(x, y, by = "key") # A tibble: 2 x 2 key val_x <dbl> <chr> 1 1 x1 2 2 x2
anti_join函数
丢弃 x 表中与 y 表中的观测相匹配的所有观测。
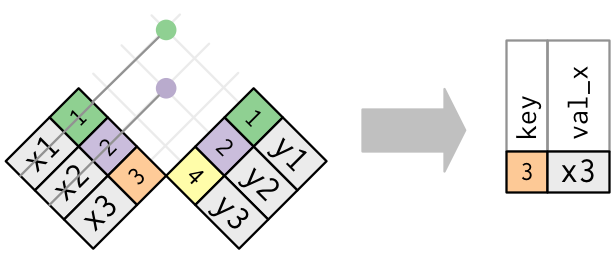
anti_join(x, y, by = "key") # A tibble: 1 x 2 key val_x <dbl> <chr> 1 3 x3
参考资料:
《R数据科学》
发表评论: